
안녕하세요, 베이글코드 데이터&AI팀 데이터 엔지니어 하석윤 입니다.
오늘은 사내 데이터 디스커버리 툴로 사용하고 있는 데이터헙(DataHub)을 도입한 여정을 소개하려고 합니다 😁
- DataHub을 왜 도입하게 되었는가?
- DataHub을 띄우자!
- Metadata Ingestion
- Airflow Integration
- 어떻게 사용하고 있나요?
- DataHub을 운영하면서 겪은 어려움
- 사내 유저들의 사용 후기
DataHub을 왜 도입하게 되었는가?
2020년부터 데이터&AI팀은 아문센(Amundsen)라는 데이터 디스커버리 툴을 도입해 사용하고 있었습니다. 그러나…
2022년 당시 데이터&AI팀은 amundsen-databuilder
4.1.0
버전을 사용하고 있었습니다. 자동화를 위해 Airflow에 amundsen-databuilder 패키지도 설치 해뒀구요. 그런데 이것이 Airflow에 설치된 다른 pip 패키지들과 충돌을 일으켰고, 결국 Airflow 업그레이드 작업을 방해하는 요인이 되었습니다.
결국 Amundsen을 대대적으로 업그레이드 하기로 계획했고, Amundsen에서 검색과 그래프 데이터베이스의 역할을 담당하는 ElasticSearch와 Neo4j도 함께 OpenSearch, AWS Neptune 등으로 교체하기로 했습니다.
하지만, 당시의 Amundsen이 AWS OpenSearch와 Neptune 지원이 제대로 되지 않았습니다. Amundsen을 직접 커스텀해야 하는 일도 있었습니다.
이렇듯 업그레이드 하는 작업이 생각보다 쉽게 이뤄지지 않았고, 덩달아 다른 작업들도 함께 블록되는 것을 보고, 데이터&AI팀에선 Amundsen은 폐기하고 다른 데이터 디스커버리 플랫폼을 찾아 새로 도입하기로 결정 했습니다.
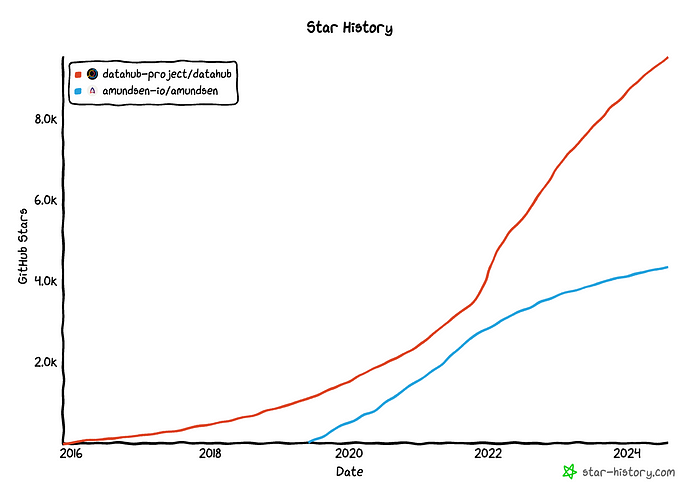
Amundsen을 대체할 새로운 디스커버리 도구를 찾던 중에 데이터헙(DataHub)라는 도구가 눈에 들어왔습니다. Github Star 갯수도 더 많고, Slack 커뮤니티도 활발한 데다가 DataHub 공식 유튜브에 각종 영상 자료도 많다는 점이 DataHub 도입을 결정하는데 긍정적인 요소가 되었습니다.
DataHub을 띄우자!
데이터&AI팀은 모든 워크로드를 Kubernetes 환경 위에서 운영합니다. DataHub도 EKS 위에서 디플로이 하였는데요. DataHub 공식 helm chart를 사용해 EKS 클러스터에 디플로이 했습니다.
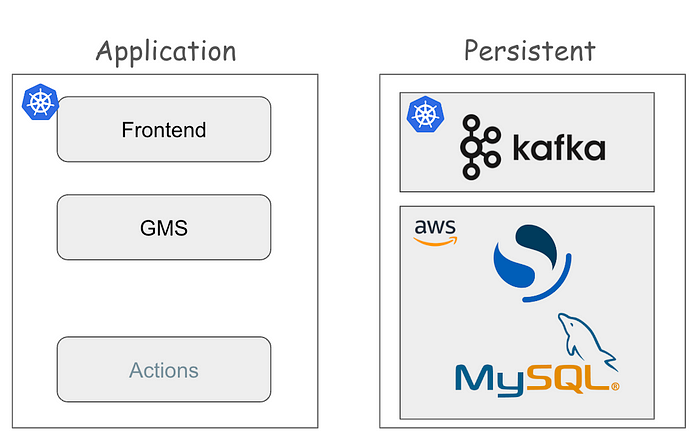
DataHub의 구조는 크게 Application Tier과 Persistent Tier로 나뉩니다. Application 단에서는 DataHub이 MSA 구조로 워크로드를 운영하는데, 쉽게 설명하면, frontend와 backend(GMS)로 구성되었다고 볼 수 있습니다. GMS는 “Generalized Metadata Service”의 약자로 메타데이터 정보를 Persistent Tier에 저장하고, 또 가져오는 역할을 수행합니다.
Persistent 영역은 각종 메타데이터가 저장되는 곳입니다. Mysql에 Table, Database과 같은 데이터 객체 뿐만 아니라, DataHub에 가입한 유저나 Tag, Glossary와 같은 메타 데이터 객체도 모두 저장돼 있습니다. OpenSearch(ElasticSearch)는 DataHub에서 메타 데이터를 검색하는 용도로 사용합니다.
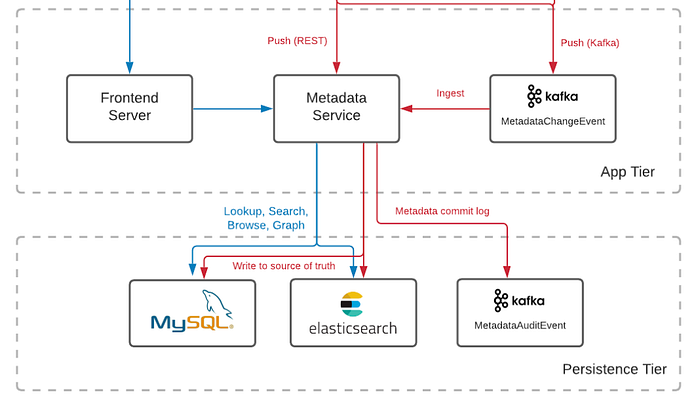
Persistent 구조에서 흥미로운 부분은 Kafka 입니다. DataHub에 어떤 테이블 정보가 추가/수정/삭제되는 이벤트나 유저가 테이블을 조회하는 정보까지 모두 Kafka에 “Metadata Commit Log”를 적재하고 있습니다.
만약 DataHub에서 event-driven action을 수행하고 싶다면 — 예를 들어 누가 어떤 테이블을 조회했다면, 그걸 slack으로 알람을 쏜다거나 — Kafka에 적재된 DataHub 이벤트를 subscribe 하는 Custom Application을 개발할 수 있도록 Event Backend가 구현되어 있습니다.
Metadata Ingestion

데이터&AI팀은 DataHub에 Databricks, Tableau, Airflow의 메타 정보를 Ingestion 하고 있습니다. Ingestion은 recipe yaml을 담은 도커 이미지를 빌드하여 Airflow에서
K8sPodOperator
를 통해 Ingestion을 자동화하고 있습니다.
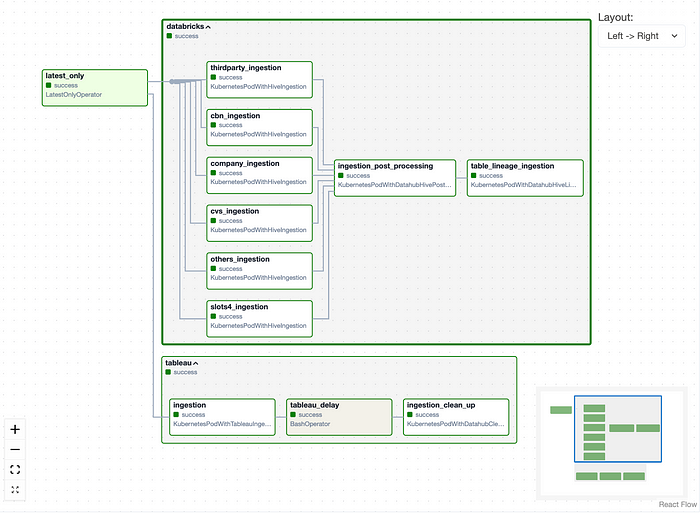
Ingestion은 daily 하게 이뤄지며, Databricks와 Tableau의 최신 정보를 DataHub에 반영 해줍니다.
Airflow Integration
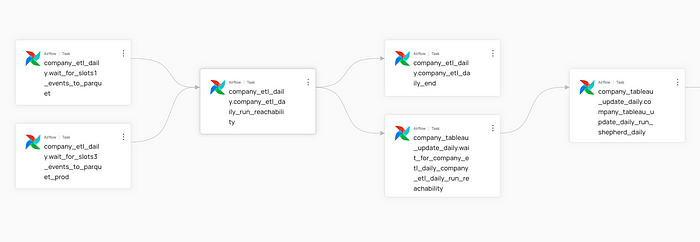
데이터&AI팀에선 Airflow를 이용해 데이터 파이프라인과 많은 작업들을 자동화 하고 있는데요. DataHub에선 Airflow Integration을 지원하여 DAG, Task 정보를 추가할 수도 있습니다. 해당 기능을 사용하려면, Airflow에 acryl-datahub-airflow-plugin을 설치해야 합니다.
DataHub의 문서에 따르면, Airflow의 OpenLineage 인터페이스를 사용해 작업별 Lineage 정보를 추출하고 DataHub에 반영(emit)한다고 합니다.
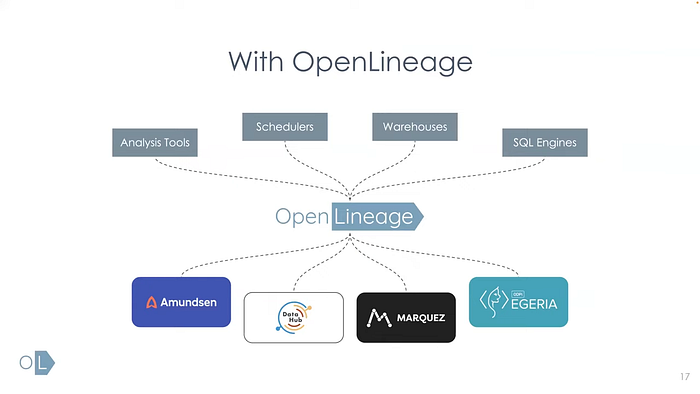
이 방식은 DataHub 뿐만 아니라 다른 Data Discovery 들도 Airflow에서 Lineage를 연동할 때 OpenLineage를 사용합니다.
Airflow 안의 Task와 Task 사이의 Lineage는 DataHub plugin을 연동하면 자동으로 추출됩니다.
그러나 S3나 Databricks Job 같이 Airflow Task가 데이터 원천으로 삼거나, 트리거 하는 대상들을 DataHub에 적재되지 않습니다.
이 경우, 아래 코드와 같이 inlets와 outlets를 직접 지정하여 Lineage에 추가할 수 있습니다.
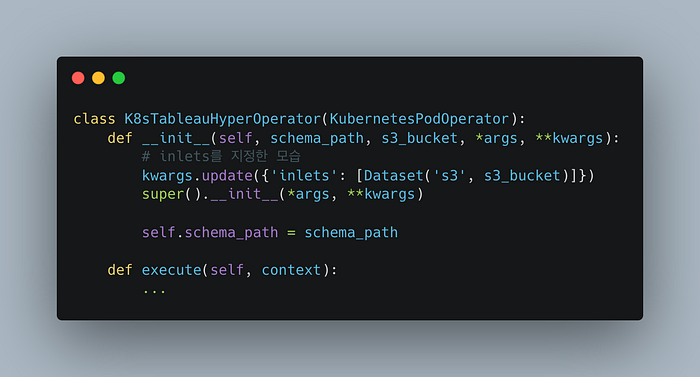

MySqlOperator
,
SnowflakeOperator
의 경우는 Airflow의 Operator 코드 상에 OpenLineage inputs, outputs 정보를 넣어주는 부분이 구현되어 있어 DataHub을 연동하면 inlets, outlets 지정 없이 바로 Mysql과 Snowflake up/down-stream을 연동할 수 있습니다.
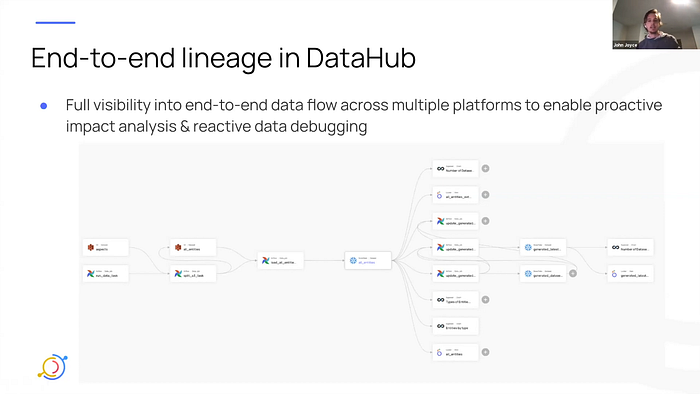
이렇게 Manual Annotation과 OpenLineage가 구현된 Operator들을 잘 사용하면, 데이터 파이프라인의 End-to-end Lineage를 DataHub에서 구축할 수 있습니다.
어떻게 사용하고 있나요?
베이글코드 데이터&AI팀은 DataHub에서 지원하는 기능들을 사용하기 위해 몇가지 기능을 커스텀 하여 사용하고 있습니다.
Databricks Table Lineage 구현
DataHub을 도입하면서 가장 필요했던 부분은 Databricks Table이 어떤 upstream으로 만들어지고, 어떤 downstream 작업들에 사용되는지 파악하는 기능이 가장 필요했습니다. 지금은 Databricks에서 Unity Catalog를 통해 Table 간의 Lineage 정보를 제공하지만, 당시에는 Unity Catalog를 사용하고 있지 않는 상황이었습니다.
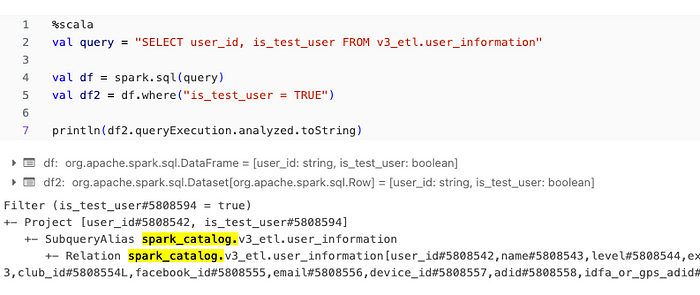
이때, Spark Dataframe의 query plan에서 쿼리 사용하는 원천 테이블을 확인할 수 있다는 점을 활용해 query plan을 파싱 해두고, 그걸 DataHub에 연동하는 방식을 채택해 Table-to-table의 Lineage를 DataHub에 구축하였습니다.
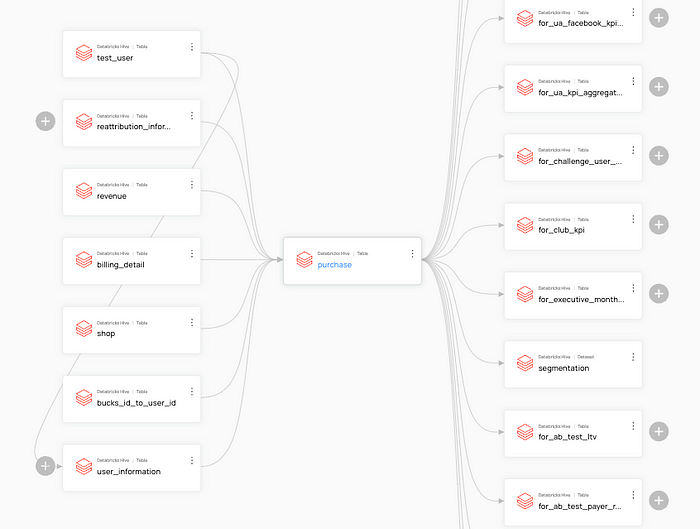
Databricks Table Lineage는 어떤 Databricks 테이블에 장애 발생 했을 때, 그것이 어떤 후속 테이블에 영향을 주는지 파악 하는 데에 도움이 되었습니다.
Manual Table Profiling
DataHub에서는 Databricks Table의 각 컬럼의 통계 정보를 확인할 수 있는 “Stats” 탭을 제공합니다.
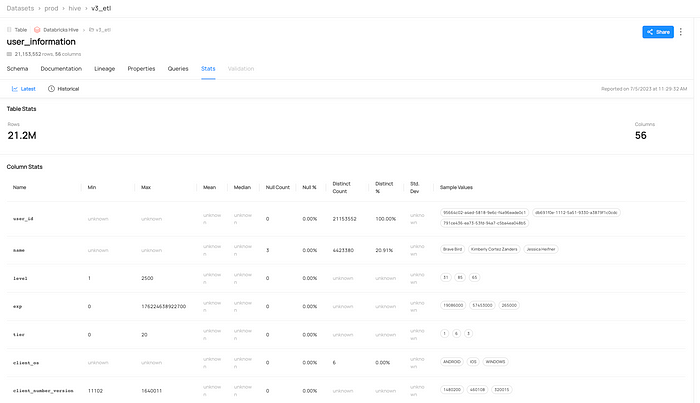
Stats 탭에서는 테이블의 Row 갯수와 컬럼별 Min/Max, Null %와 Sample Values 등을 제공하여 테이블에 대한 대략적인 정보를 확인할 수 있습니다. 그래서 이 테이블이 언제부터의 데이터를 담고 있는지, 컬럼에 들어가는 데이터 형식은 어떤지 등을 DataHub에서 바로 확인할 수 있습니다.
해당 기능은 DataHub의 Databricks Ingestion에서
profiling.enabled
를 true로 설정하면 Ingestion 때 통계 정보를 함께 쿼리 합니다. 하지만, (1) Profiling을 Ingestion 주기에 맞춰 진행해야 한다는 점, (2) Profiling 작업이 추가되어 Ingestion 속도도 그만큼 느려진다는 점, (3) 그리고 Ingestion recipe에서는 컬럼 별로 Stats 계산을 커스텀 하기어렵다는 점이 해당 기능을 도입하는데 걸림돌이 되었습니다.
그래서 Profiling은 데이터&AI팀의 니즈에 맞게 코드를 직접 구현하고, 스케쥴 주기를 조정해 DataHub에 반영하는 방식으로 운영하고 있습니다.
테이블이 생성되고 삭제되는 정보는 좀더 즉시 반영 되어야 유저들의 UX를 해치지 않을 것 같아 Ingestion은 하루에 한 번 주기로 돌리고, 테이블의 Profilie 정보는 대략적인 정보로 테이블을 파악하는 용도이기 때문에 일주일에 한번 돌리고 있습니다.
Ingestion은 DataHub의 Ingestion Recipe 방식으로 운영하고, Profiling은 아래와 같이 커스텀 코드를 구현해 통계 정보를 추출한 후, DataHub에 반영합니다.
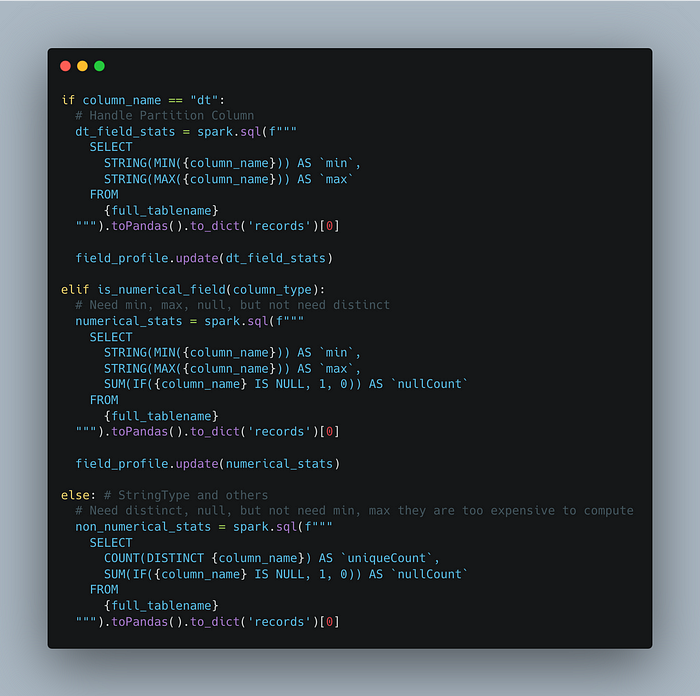
이렇게 코드를 구성한 이유는 numeric 컬럼은 min, max, null count를 계산하는 게 쉽지만, distinct count는 굳이 필요하지 않고, string 컬럼은 distinct count, null count를 계산하기는 쉽지만, min/max-length string을 구하는 건 계산 비용이 많이 든다고 판단해 위와 같이 코드를 구성했습니다.
DataHub을 운영하면서 겪은 어려움
DataHub가 팀의 Data Context와 검색과 Lineage를 통한 Discovery 기능을 제공하고 있지만, DataHub은 직접 디플로이 하고, 운영하면서 몇가지 어려움을 겪었습니다.
DataHub 버전 업그레이드 장애
데이터&AI팀은 DataHub을
v0.9
버전부터 사용하기 시작하여 현재
v0.13
버전까지 신규 버전이 나올 때마다 업그레이드를 진행하여 DataHub의 최신 기능을 사용하고 있습니다.
업그레이드를 진행하면, 신규 기능을 사용해 볼 수 있다는 장점도 있지만, 업그레이드 진행 중이나 이후에 서비스가 불안정 해지는 상황도 종종 겪었습니다. 데이터&AI팀이 겪었던 사례 중 하나를 소개 하고자 합니다.
DataHub은 지금까지 활발히 개발되고 있고, 기존 Entity에 메타 데이터를 추가하거나 삭제하는 등 Entity의 스키마의 변화가 잦은 편입니다. 예를 들어,
v0.13.3
버전에서는 “Business Attribute”라는 속성이
Dataset
Entity에 추가되는 사항이 있었습니다.
만약 Entity Schema에 변경 사항이 있다면, DataHub 업그레이드 과정에서 ElasticSearch에 저장된 Entity의 index의 mapping을 신규 스키마에 맞게 업데이트 해줘야 합니다.
DataHub 업그레이드는 이 과정을 안전하게 진행하기 위해 ES의 reindex API를 통해 기존 index의 복제본을 만든 후 업그레이드를 진행합니다. 그래서 업그레이드가 실패해도 복제한 index에서 데이터를 복구할 수 있습니다.
데이터&AI팀이 겪은 장애는 버전을
v0.12.1
에서
v0.13.0
로 올리는 과정에서 발생하였는데요.
v0.13.0
버전에서는 데이터의 장애 상황을 기록하는 “Data Incident”라는 속성이 추가되었고, 기존 ES index에 변경된 Entity Schema를 반영 해줘야 하는 일이 생겼습니다.
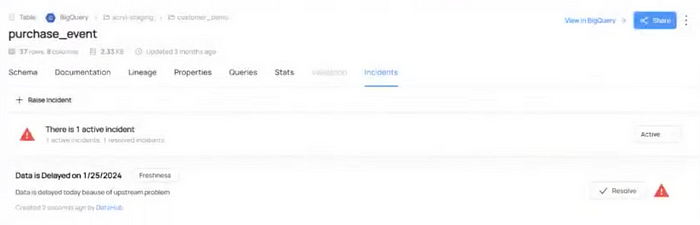
그래서 업그레이드 과정에서 reindexing이 발생 하였는데… reindexing이 끝나지 않고 몇 시간이나 지속되는 문제가 발견 되었습니다 😱
원인은 DataHub-Airflow 연동에 있었습니다. Airflow Task Run 정보가 DataHub에 실시간을 계속해서 업데이트가 되면서, Reindexing를 해도 기존 index와 Document Count가 맞지 않게 되었습니다. Datahub의 경우, 기존 index와 Reindexing 한 index의 문서 갯수가 맞지 않으면 갯수가 맞을 때까지 reindexing을 하는 로직이 있습니다. [github code]
Airflow에서 DataHub으로 데이터는 계속 들어오지, DataHub은 reindexing 한 것과 기존 index랑 문서 갯수는 계속 안 맞지… 업그레이드 작업이 결코 끝날 수 없었습니다.
결국 DataHub-Airflow 연동을 잠시 중단 시킨 후에, DataHub 업그레이드를 진행 했고, 그 결과 문제 없이 업그레이드를 성공할 수 있었습니다 😌
이후에 알게된 내용이지만, DataHub helm-chart에서 업그레이드 관련 구성을 세팅할 수 있는데,
allowDocCountMismatch
를 true로 설정 했다면, 도움이 되었을 수도 있을 것 같습니다. 다만, DataHub 코드를 확인해보니, 8시간 동안 reindexing 과정을 수행한 후에도 해결이 안 되면, 문서 갯수가 안 맞아도 패스한다는 로직이기 때문에 업그레이드가 완료 되기 까지 오래 기다리긴 했을 것 같습니다.
너무 큰 Ingestion Log
DataHub의 Ingestion을 Airflow로 자동화 한 후, 해당 Ingestion DAG에 쌓이는 Airflow Task Log가 너무 크다는 점을 발견하였습니다.
Databricks에서 4000개 테이블을 Ingestion한
.log
파일이 20.4 MB 정도로 다른 로그 파일들에 비해 큰 편이라, Airflow web에서 로그를 볼 때 웹서버에 부하가 온다는 피드백이 있었습니다.
코드를 디버그 해보니 DataHub CLI 쪽에서 “CLI Report”라는 이름으로 60초에 한 번씩 Ingestion 현황을 출력하는 코드가 있었습니다.
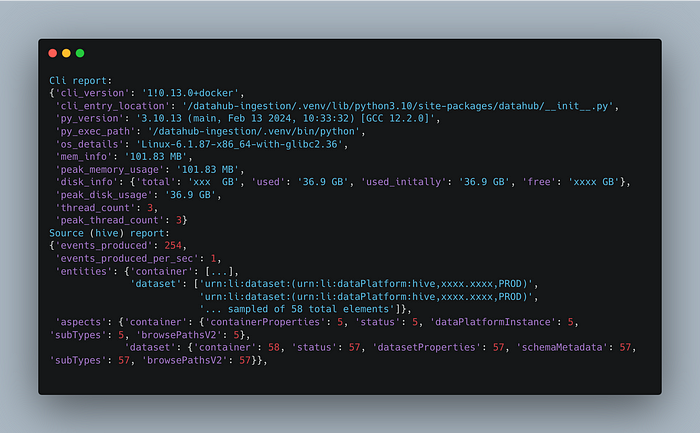
이 부분이 Ingestion Log의 상당 부분을 차지 한다는 것을 발견하고, 유저가 원하면 CLI Report를 출력하지 않도록 하는
--no-progress
옵션을 추가하는 PR을 DataHub에 올렸고, 다행히 리뷰 후에 DataHub에 반영까지 되었습니다.
feat(ingest): add ingest
--no-progress
option
덕분에 Ingestion Log는 2.3 MB까지 줄어들어, 기존 대비 10% 수준으로 로그 파일 사이즈를 낮출 수 있었습니다.
DataHub의 Event Backend인 Kafka 클러스터
DataHub은 유저가 메타 데이터를 검색하거나, 수정 하는 등 DataHub 내에서 발생하는 각종 이벤트를 Kafka에 적재하여, Event-driven 액션을 수행할 수 있도록 지원합니다.
하지만, 현재 베이글코드에선 DataHub의 이벤트를 기반으로 어떤 액션도 수행하고 있지 않아서 Kafka에 이벤트가 쌓이기만 하고, 이를 사용하는 Event-driven Action을 하지 않고 있습니다
DataHub requires Kafka to operate. Kafka is used as a durable log that can be used to store inbound requests to update the Metadata Graph (Metadata Change Proposal), or as a change log detailing the updates that have been made to the Metadata Graph (Metadata Change Log). — DataHub Document
Kafka에 쌓인 데이터가 DataHub GMS나 Frontend가 동작하는 데에는 아무런 역할도 수행하지 않는 것을 보고, Kafka로 이벤트를 쏘지 않도록 설정하고 싶었지만, 해당 기능을 지원하지 않습니다. 즉, DataHub을 쓰려면 Kafka Cluster도 반드시 필요한 것이죠. 언젠가 Kafka Produce를 선택적으로 할 수 있는 기능이 개발되면 좋을 것 같습니다.
DataHub에 PR을 열기도 하며
DataHub도 그 자체로 완벽한 플랫폼은 아니었습니다. 도입하며 운영하는 중에도 몇 가지 개선점들이 보여 데이터&AI팀에서 직접 PR을 열어 반영하기도 했습니다. 오픈소스를 그대로 사용하기만 하는게 아니라 불편한 점의 수정을 제안하고, 오픈소스에 기여 하며 팀이 성장하는 좋은 경험이었습니다.
feat: Default User Credentials
feat(ingest): add ingest
--no-progress
option
사내 유저들의 사용 후기
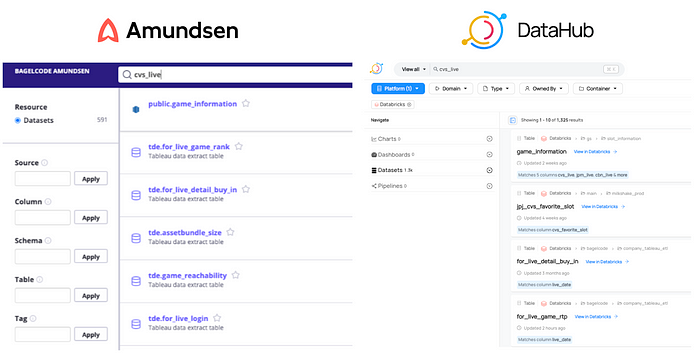
DataHub 도입 이후 Amundsen 때보다 검색이 더 정확 해졌다는 의견이 많았습니다. 두 플랫폼 모두 ElasticSearch를 기반으로 검색 기능을 제공 하는데, DataHub 쪽이 어떤 Column을 포함하고 있어서 검색 결과에 포함 하고, 데이터 필터링 기능이 훨씬 간단 했습니다.
DataHub 서비스를 데이터&AI팀보다 게임팀의 BA 분들이 더 자주 사용하는 현상도 발견 되었습니다.
데이터&AI팀은 Databricks의 “Catalog” 탭에서 확인하거나, 이미 쌓인 경험 등을 바탕으로 DataHub 검색까지 도달하지 않는 모습을 보였습니다. 반면 게임팀의 BA 분들은 Databricks에 접근할 수 없어, 쿼리 작성을 위해 데이터를 검색할 플랫폼이 필요했고, 그 용도로 DataHub을 사용하고 인사이트를 얻는 모습이 보였습니다.
마무리
긴 여정 끝에 베이글코드는 DataHub을 성공적으로 도입해 사용하고 있습니다.
베이글코드는 Data-driven Company 입니다. 그리고 사내 데이터를 구성원 모두가 접근하고 활용할 수 있도록 데이터 민주화(Data Democraization)를 추구합니다. 사내 데이터를 탐색할 수 있는 Data Discover Platform은 구성원 모두가 데이터를 민주적으로 접근하고 인사이트를 얻는데 중요한 요소입니다.
DataHub을 도입하면서, 단순히 플랫폼을 도입하는 것만으로 이런 가치를 획득하는 게 아니라는 생각을 하게 되었습니다. 메타 데이터를 어떤 주기로 반영하고, 사람들이 테이블을 쉽게 이해할 수 있도록 Metadata를 보강하고, 큐레이션 하는 것들. 즉, 플랫폼을 잘 운영하는 것이 더 중요한 것을 배울 수 있었습니다.
앞으로 더 많은 사람들이 데이터에서 가치를 발견하길 바라며, 긴 글 읽어주셔서 감사합니다.
Members
- Seokyun Ha, 하석윤 | Data Platform Team Leader
- Kyeonghoon Kim, 김경훈 | Data Engineer
- Imsong Jeon, 전임송 | Jr. Data Engineer