
부제: Airflow 모니터링과 알림 노하우
안녕하세요, 베이글코드 데이터&AI팀의 데이터 엔지니어 하석윤, 김경훈 입니다.
저희는 Airflow 2nd 밋업에서 “Airflow DAG 좀 살려주세요!”라는 주제로 발표를 진행하였는데요.
이번 포스트에서는 발표 내용을 글로 정리해 전달 드리고자 합니다!
데이터&AI팀은 Airflow를 통해 모든 데이터 파이프라인을 자동화 해 운영하고 있습니다.
원천 데이터 수집과 적재, Spark ETL, 그리고 각종 지표 Alert 그리고 ML/DL 모델 학습까지 Airflow가 모든 것을 관리해주고 있습니다.
그러나 작업을 Airflow에서 DAG를 자동화 하였다고 해서 끝나는 게 아닙니다. 아주 여러 이유로 Airflow에 스케쥴링 한 작업이 실패합니다.
스케쥴링 했던 작업이 데이터가 늘어나면서 Timeout을 겪을 수도 있고, API 호출을 하는 벤더 사에 장애가 발생하거나, DAG 로직 자체에 오류가 있었을 수 있습니다. 데이터 엔지니어의 유지·보수 작업은 Airflow 작업 실패에서 시작합니다. 기존에 자동화 해두었던 작업이 실패하게 되면 데이터 엔지니어가 살펴봐야 하죠.
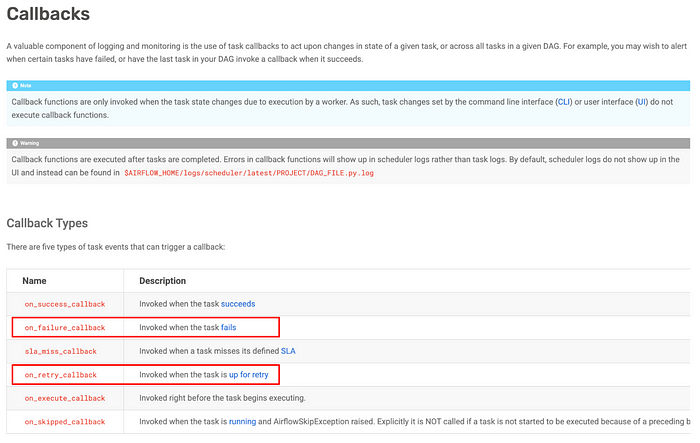
Airflow는 Task가 실행되는 과정에서 발생하는 각종 이벤트에 특정 동작을 실행할 수 있도록 callback 인터페이스를 지원 합니다. 성공, 실패, SLA miss, 재실행와 실행, 스킵될 때 특정 행동이 트리거 되도록 지정할 수 있습니다. 이번 글에서는
on_failure_callback
과
on_retry_callback
을 어떻게 커스텀 했는 지를 중점적으로 소개 드리고자 합니다.
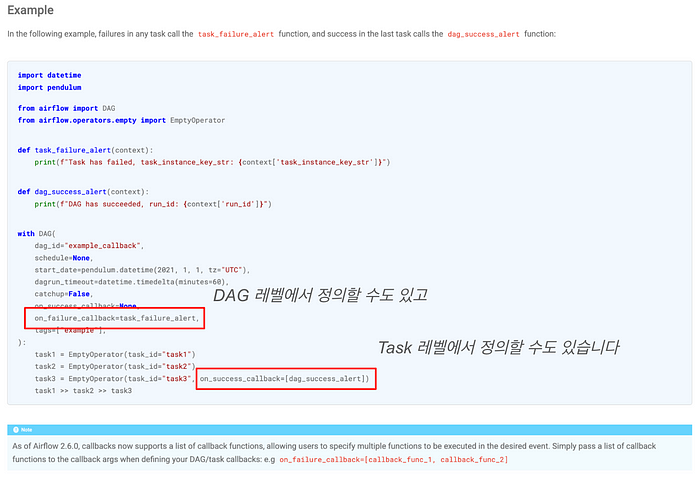
Airflow 공식 문서에 있는 예제 코드인데요. Task에 대한 callback을 DAG 레벨에서도 정의할 수 있고, Task 레벨에서도 정의할 수 있습니다. Airflow 2.6.0 버전부터는 여러 개의 callback을 정의하는 것도 가능하다고 합니다!
Airflow Alert 메시지 개선의 여정
Airflow Callback 기능에 대해 간단하게 소개드렸고, 지금부터는 베이글코드가 어떻게 얼럿을 개선했는지 스토리를 소개 해보겠습니다!
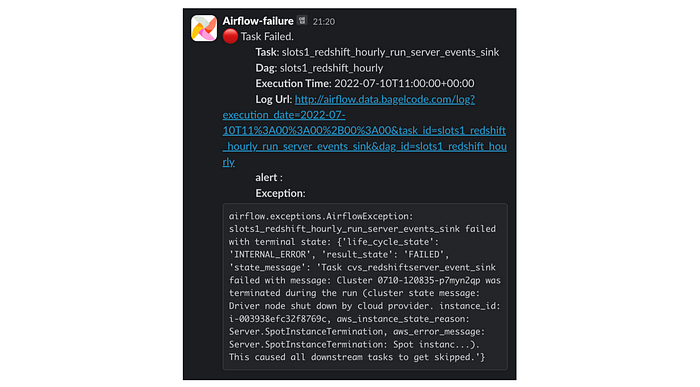
평소처럼 한 명의 데이터 엔지니어가 slack 채널에서 장애 메시지를 발견 합니다.
‘오늘은 어떤 작업이 터졌을까…?!’
위 캡처는 베이글코드에서 몇 년 동안 사용하던 에러 메시지인데요. 저도 회사에 입사한 이후로 3년 넘게 저 메시지를 보면서 작업을 디버그 했습니다. 그런데 어느 순간 이런 생각이 들었습니다.
이게 최선일까?
Task는 얼마나 실행된 건지, 어떤 Operator가 실패한 건지, 디버그 해야 하는데 어디를 들어가야 하는지도 안 나와 있었습니다. 저희는 기존 메시지를 더 개선할 수 있다고 생각했고, 작업을 시작 했습니다!
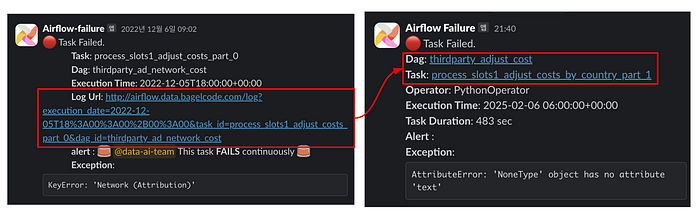
일단 첫 번째 개선에서는 기존에 지저분하게 있던 Raw URL에 Alias를 부여 했습니다. DAG 웹페이지에도 바로 접속할 수 있도록 링크도 추가하였습니다.
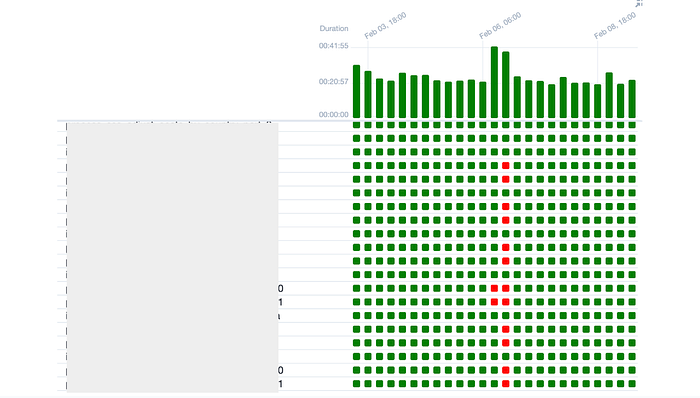
DAG 페이지에 대한 링크를 추가한 이유는 종종 DAG에 속한 전체 Task를 보면 디버그가 쉬워지는 경우가 있기 때문입니다.
캡처는 데이터를 받아오는 벤더사의 API가 잠시 불안정 했고, 이후에는 복구 되어 자연 회복된 모습입니다. 이렇게 전체 DagRun 기록을 보고 빠르게 의사결정을 내릴 수 있습니다.
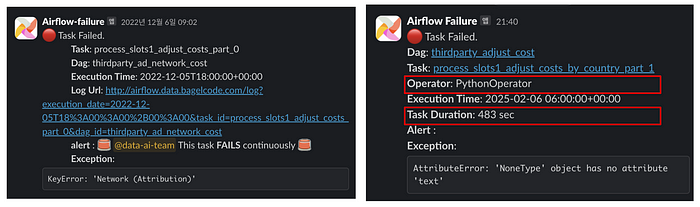
또, 어떤 작업이 실패한 것인지 명확하게 전달하기 위해 Operator 종류를 표시하도록 했습니다. 그리고 Task가 얼만큼 돌다가 실패한 것인지도 Task Duration 정보도 메시지에 추가하였습니다.
만약 Task Duration이 너무 짧았다면, 데이터를 가져오는 초반 부분에 문제가 있었을 거라 생각할 수 있고 실행이 좀 된 상태로 실패했다면, 로직 중간에 문제가 있거나 데이터 중 일부가 잘못 되었을 수 있습니다. 만약 실행 시간이 timeout에 가까웠다면, timeout을 늘려주는 걸로 해결할 수도 있습니다.
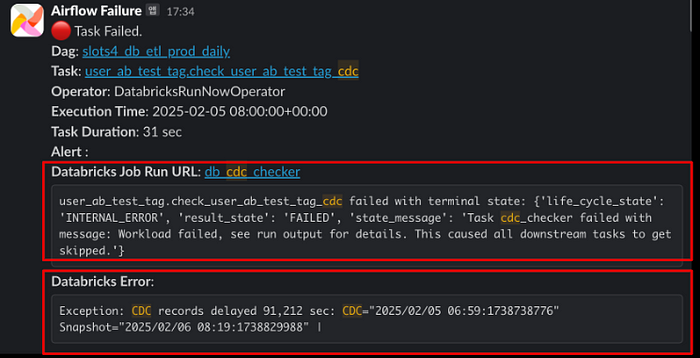
다음으로는 저희가 Airflow를 통해 외부 플랫폼에서 수행하는 작업의 에러 메시지를 개선한 사례를 공유 드리겠습니다.
베이글코드는 각종 대규모 배치 처리를 Spark을 통해 수행하고 있습니다. 그리고 Databricks 플랫폼을 활용해 spark job을 운영하고 있습니다. 저희는 800개 이상의 Databricks job을, houry 또는 daily 하게 수행하며 하루에 15,000 건의 Spark 작업을 Databricks에서 돌리고 있습니다. 이 숫자는 Airflow로 자동화 한 작업 중 절반에 해당하고 그래서 Databricks 관련한 얼럿 메시지가 가장 많이 발생합니다.
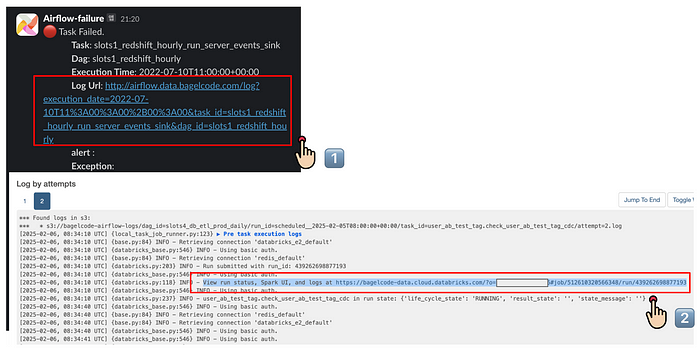
개선 전의 과정을 잠시 보여드리겠습니다. 먼저 엔지니어는 얼럿 메시지에 있는 링크를 클릭 합니다. Airflow 웹페이지의 Task Log에서 Databricks에서 실행한 Job의 Run URL을 찾아서 클릭합니다. 그러면 Databricks 웹콘솔에 접속해 어떤 Exception이 발생했는지 확인할 수 있습니다!
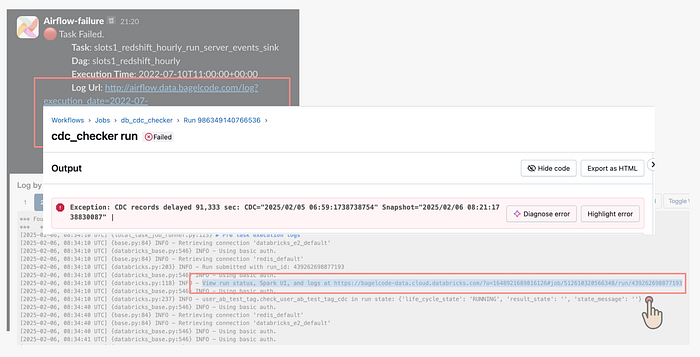
엔지니어는 2번의 클릭을 했고, 웹페이지도 2번 이동 했습니다. 각 페이지가 로딩되는 시간도 걸릴 테니 좀 답답하겠죠? 그리고 이 과정은 모바일 환경에서 하기에는 더 끔찍했습니다. Airflow와 Databricks 둘 다 모바일뷰에는 최적화 되어 있지 않았거든요. 저희는 이 끔찍한 경험을 개선하기로 마음 먹었습니다!
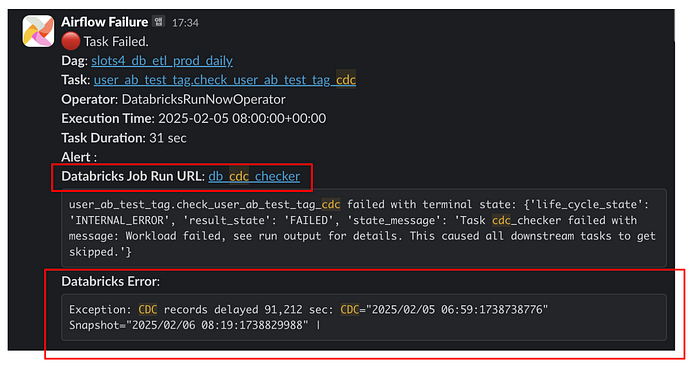
개선된 결과는 위와 같습니다. 먼저 Airflow 웹페이지를 통해 접속했던 Databrickcs Job Link가 에러 메시지에 포함 되었습니다. 클릭 한번을 줄였고요. Task가 실행한 Databricks Job Run에서 API 호출을 통해 에러 로그를 가져왔습니다. 이것을 에러 메시지에 넣어서 어떤 에러인지 볼 수 있도록 개선하였습니다.
다음으로 Airflow에서
K8sPodOperator
로 자동화 한 작업들의 얼럿 메시지를 개선한 경험을 공유 드리고자 합니다.
저희는 운영 db에서 데이터를 수집해 s3에 적재하는 과정과, s3에 있는 Tableau 데이터소스를 업로드 하는 과정을 Airflow로 자동화 하고 있습니다. 개선된 메시지를 바로 살펴보겠습니다.
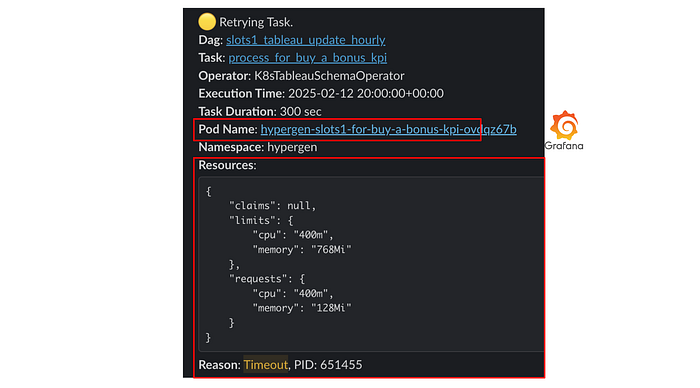
Airflow의 Pod Operator는 작업 실패 후에, 에러 로그에 Kubernetes Pod에 대한 리소스 명세를 제공 합니다. 이곳에서 리소스 할당량과 에러 이유를 스크랩 해 에러 메시지에 첨부하였습니다. OOM killed 상황이나 Node storage outage와 같은 상황을 본 메시지를 통해 쉽게 발견하고 대응할 수 있게 되었습니다.
데이터&AI팀은 모든 Pod의 리소스 사용과 정보를 Prometheus를 통해 수집하도록 연동하였는데요. 에러 메시지에서 해당 Pod의 Grafana 대시보드로 이동할 수 있도록 링크를 제공합니다.
Grafana 대시보드에 접속하면, 이런 식으로 Pod이 실행된 기간 동안의 리소스 사용률을 확인할 수 있습니다. 리소스 사용 패턴을 빠르게 확인해, timeout을 늘리거나 cpu, memory limit을 조정하는 방식으로 대응하고 있습니다.
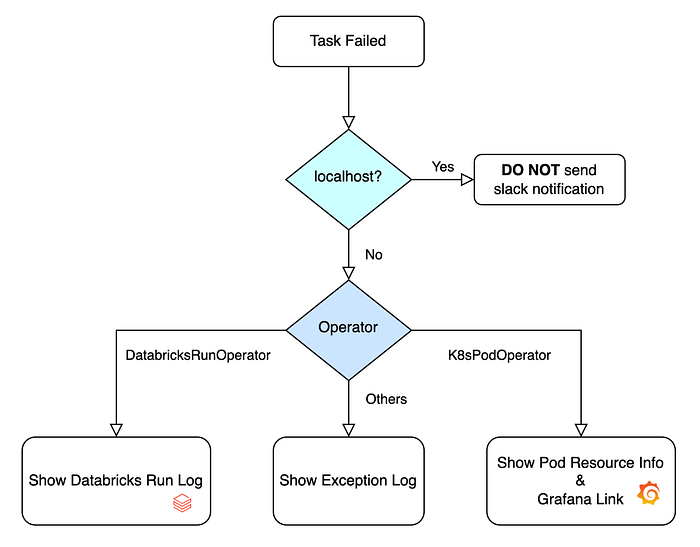
지금까지 공유 드린 내용을 종합해 플로우 차트로 그려보았습니다.
로컬에서 Airflow를 실행하며 테스트 할 때는 알람을 보내진 않습니다. Production 환경에서 Operator 종류에 따라, 니즈에 맞게 다른 에러 메시지를 렌더링 제공하고 있습니다.
지금까지 저희가 에러 메시지를 개선한 일련의 경험을 공유 드렸는데요. UI/UX 디자인에는 3-click-rule라는 원칙이 있습니다. 사용자는 클릭이 많고, 웹페이지 이동이 많아질 수록 피로감을 느끼고 서비스에서 이탈하게 됩니다. 그동안의 에러 메시지는 3-click 이상을 요구 했습니다. 그래서 사람들이 failure 로그를 덜 살펴보게 되고, 가끔은 문제가 방치될 수 있습니다. 에러 메시지에 대한 일련의 개선은 Data Scientist, Data Engineer의 시간 몇 초를 아끼고, 문제를 디버그 하는데 더 집중할 수 있도록 하였습니다.
부가적으로 얻은 장점은 mobile-friendly! 인데요. 에러 메시지가 풍성해지면서, 에러 메시지만으로도 대략적인 상황을 파악할 수 있게 되었고. 맥북 없이도 출퇴근 길이나 침대에서도 모바일 슬랙을 통해 에러 상황에 쉽게 접근할 수 있게 되었습니다.
Airflow DAG Ownership
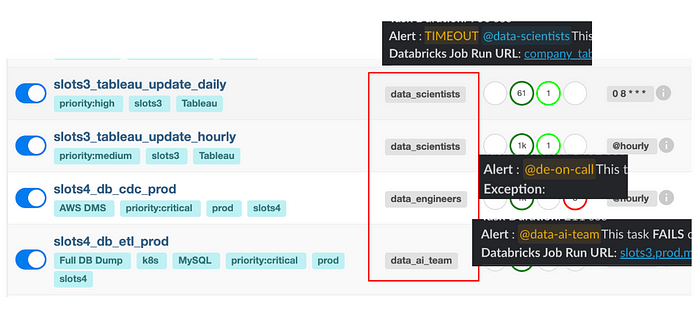
데이터&AI팀은 Data Scientist, Data Engineer, AI Engineer를 포함해 20명의 인원으로 구성 되어 있는데요. 인원이 많아지면서, 전체를 태그하는 알람은 조금 노이지 하다는 의견이 있었습니다. 그래서 DAG 별로 Owner를 지정 DS가 운영하는 DAG는 DS 팀을 태그하도록, DE가 운영하는 DAG는 DE 인원을 태그하도록 커스텀 했습니다.
Airflow and Engineering KPI
또 어느 날 한 명의 데이터 엔지니어가 이런 생각을 합니다.
음… 오늘은 좀 많이 터진 것 같은데?
음… 오늘은 좀 잠잠하네~~ (플래그 성 발언…)
그리고 이 생각은 그래서 오늘이 정말 잠잠한 날이었을까?라는 생각으로 이어졌고, 데이터&AI팀에서 하루에 얼만큼 Airflow retry와 failure가 발생하는지 세어보고 싶다는 생각으로 이어졌습니다.
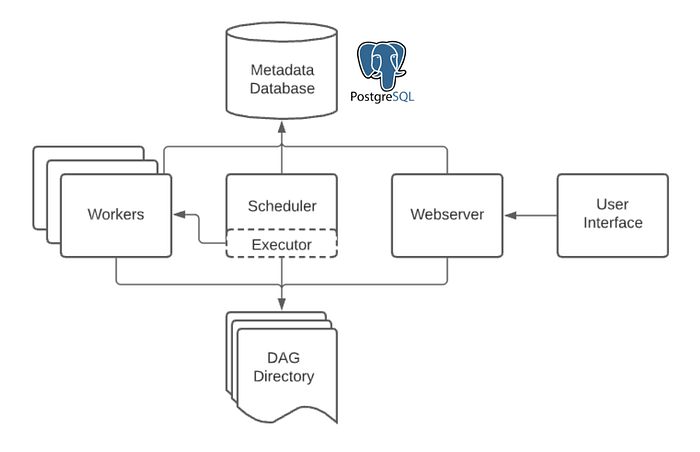
Airflow 구조를 살펴보면, Metadata Database가 존재합니다. 그리고 엔진으로는 PostgreSQL을 사용합니다. 이 데이터베이스에는 Airflow User나 Connection, Variable에 대한 정보 뿐만 아니라 Task Instance에 대한 실행 기록도 모두 담겨 있습니다. Airflow에서는 이 Database에 쿼리할 수 있는 코드를 제공하는데요.
@provide_session
라는 데코레이터를 함수에 붙여주면, 이 함수에서 postgresql session에 접근할 수 있고, 이를 통해 특정 기간 동안의 airflow에서 실패한 task run 기록 횟수를 세어 볼 수 있습니다. 즉, Ariflow Task에서 Ariflow 자체에 대한 정보를 수집하는 것이 가능합니다.
저희는 이를 활용해 하루에 몇 건의 Task가 실패하는지 일일 얼럿을 개발하였습니다.
살펴보면 retry는 꽤 자주 있지만, fail은 그보다 적게 발생하는 걸 볼 수 있습니다. retry가 많은 이유는 sensor 때문인데요. Sensor timeout으로 인한 오류가 빈번히 발생합니다. 또는 AWS EC2의 Spot Termination로 인해 Spark job 작업이 중단 되는 경우도 있는데요. 그 이후엔 작업이 대부분 성공하기 때문에 retry는 하지만 fail 하는 경우는 비교적 적습니다.
저희는 이 지표를 Data Engineer의 KPI로 설정해, 줄여나가는 것을 목표로 하고 있습니다. 다만, AWS 장애나 벤더사 장애 등등 외부적인 요인에 의해 작업이 실패하는 경우가 종종 있습니다. 그래서 현재는 retry 추세가 어떻게 되는지 수집 모니터링 정도만 진행하고 있습니다.
Splunk Integration
베이글코드에서는 Splunk를 이용해 APM 및 로그 데이터를 수집하고 있습니다.
Splunk에 대해 생소하신 분들을 위해 간단히 소개해드리자면 로그 데이터를 수집, 저장, 분석하는 SIEM(Security Information and Event Management) 및 로그 관리 솔루션 입니다. 다양한 데이터 소스를 연결해 실시간으로 로그를 분석하고 보안 이벤트를 모니터링 할 수 있습니다. 저희는 Airflow의 Task Run 로그를 Splunk Index로 저장하고, 쿼리를 통한 분석과 용도로 사용 중입니다.
이런 의문을 가질 수 있습니다. 성공 및 실패 여부는 Airflow DB에서 쿼리가 가능하고 Error 로그도 AWS S3 등 저장해 놓은 경로에서 확인할 수 있는데 굳이 Splunk에 적재할 필요가 있을까?
위는 맞는 말이지만 S3에 저장해 놓은 로그는 S3 파일을 열어보기 전에는 그것이 실패한 것의 로그인지 알기 어렵습니다. 또 Splunk에 Index로 적재하면, 에러 로그 텍스트를 빠르고 쉽게 쿼리할 수 있습니다.
Splunk Index에서 로그 데이터를 수집하기 전에 어떤 데이터를 넣을지 먼저 고민해야 합니다. 저희는 아래 요소를 수집하기로 했고 특히 Error Log를 위주로 수집하기로 했습니다.
- Dag id
- Task id
- Operator type
- Duration
- Error log
- etc…
어떤 것을 적재할지 정했으니 이제
on_failure_callback
에 splunk에 적재하는 코드를 추가해주면 됩니다.
위와 같이 기존
SlackNotifier
에 “Send to Splunk” 부분을 추가 로그를 적재하고 있습니다.
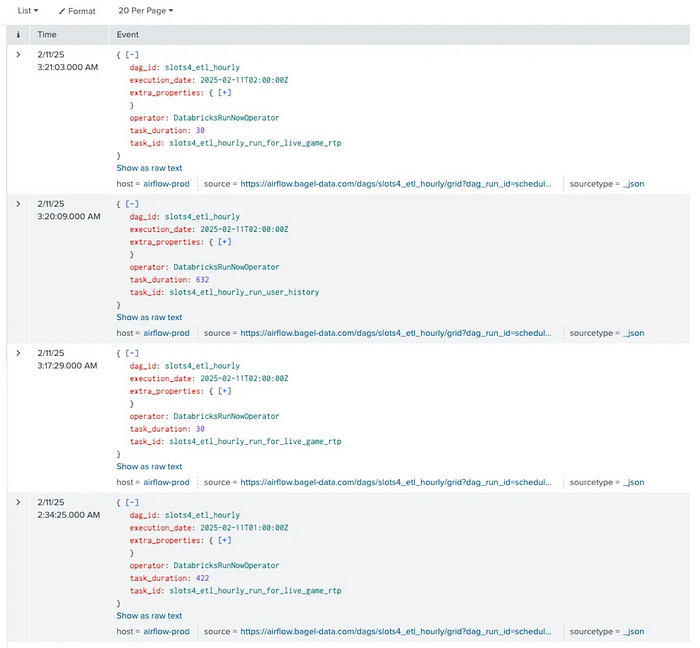
Splunk 적재 후에는 위와 같이 dag_id를 기반으로 쿼리를 할 수도 있고 에러 로그 별로 집계를 해볼 수도 있습니다.
splunk에서는 대시보드 기능도 제공하고 있습니다. 앞에서 언급했던 kpi를 살펴보기 쉽게 대시보드를 생성해두었습니다. 각각 당일 실패 횟수, 각 날짜별 실패 횟수, DAG id별 실패 횟수, Operator별 실패 횟수를 나타냅니다.
기존 모니터링 시스템의 한계
데이터&AI팀에서 Airflow retry/failure 수를 KPI로 정하고 이를 장기적으로 줄이는 것을 팀 목표로 정했지만 기존 모니터링 시스템의 한계를 느꼈습니다. Slack Failure Alert, Splunk Dashboard로 이를 모니터링하고 있지만 각각 부족한 점이 있습니다.
Slack Failure Alert
- 로그 분석의 번거로움: 실질적인 실패 원인을 파악하기 위해 로그를 직접 확인 및 분석해야 함.
- 트렌드 파악의 어려움: 알림 메시지 만으로는 장기적인 트렌드 파악이 어려움
Splunk Dashboard
- 접근성 부족: 매번 splunk에 로그인 하는 과정이 필요해 의도적으로 보려고 노력해야 함.
- 개선 방향 부재: 로그를 단순히 집계할 뿐 장기적인 개선을 위한 방향성을 제시하지는 않음
Weekly Airflow Report

기존 모니터링 시스템의 한계를 극복하기 위해 Error log를 모아서 GPT에 넣은 후 리포트를 작성해보자는 아이디어가 제시되었고 이를 데이터 엔지니어 전임송 님께서 주도적으로 구현해주셨습니다.
처음에는 가장 간단한 방법으로
- splunk에서 7일 간의 로그를 가져오기
- airflow에서 prompt를 합친 후 gpt에 보내기
- 리포트를 작성하고 이를 slack으로 보내기
의 구조로 구현을 해보았습니다.
하지만 로그를 그대로 넣으면 TPM(Tokens Per Minute) 초과가 일어나는 문제가 발생했습니다. 일반적인 TPM 초과는 1분을 기다렸다 다시 보내면 되지만 에러 로그의 양 자체가 많은 상태에서 텍스트를 임의로 쪼개면 에러 로그 사이가 끊겨 context를 제대로 파악하지 못하는 문제가 있습니다.
이런 TPM 초과 문제를 해결하기 위해 Divide and Conquer 방식을 사용하기로 했습니다. 먼저 각 Raw log를 같은 dag_id, task_id를 가지면 한 Log Entry로 분류를 하고 이를 집계합니다. 이후 서로 다른 task라도 같은 dag 내에서 발생하는 error는 연관성이 있을 것이라 가정하고 같은 dag에서 발생한 error를 같은 Log Group으로 묶습니다.
토큰을 효율적으로 사용하기 위해 Log Bin을 만들고 이를 토큰 허용 범위 내에서 Log Group으로 채웁니다.
전체적인 과정을 살펴보면 raw log를 각 Log Bin으로 쪼개고 각각 ChatGPT에 보내 divided summary를 생성합니다. 이후 각 divided summary를 모두 합쳐 다시 ChatGPT에 보내 최종 report를 생성합니다. (divided summary와 conquer summary를 생성할 때는 다른 프롬프트를 사용합니다.)

위의 여러 과정을 거쳐 최종적으로 생성한 Weekly Report 입니다. 한 주간의 전반적인 summary를 알려주고, 스레드 댓글로 각각의 세부적인 내용과 개선 제안을 주도록 되어있습니다.
아직 Weekly Report가 완벽하지는 않습니다. 오른쪽 사진의 detail을 보면 Spot Instance Issue에 대한 해결책으로 On-demand를 사용하는 것을 제안했는데 Spot Instance의 목적이 비용 절감임을 생각해보면 오히려 Spot Instance Issue가 덜 발생하는 Instance 타입이나 AWS AZ를 추천해주는 것이 바람직합니다. 이런 문제점을 인지하고 있고 이외에도 이전 주 Report와 이번 주 Report를 비교하는 부분을 추가하는 등 개선을 위해 노력하고 있습니다.

처음 시작할 때, 데이터 엔지니어의 하루는 Airflow 작업이 실패하는 것에서 시작한다고 말씀 드렸는데요. DAG를 살리기 위해 로그를 추적하고, 원인을 분석하며, 같은 문제가 반복되지 않도록 하는 것 만을 중요하게 생각했었죠. 하지만 저희는 단순한 반복 작업에서 벗어나, 더 효율적인 문제 해결 방법을 고민하기 시작했습니다.
이를 위해 Slack 메시지를 3-click-rule에 맞춰 직관적으로 정비하고, 에러 로그를 Splunk에 적재 체계적으로 관리하기 시작했습니다. 더 나아가, ChatGPT를 활용한 주간 리포트 자동 생성을 통해 장애 대응 프로세스를 지속적으로 최적화하고 있습니다.
이러한 개선을 거치며 데이터 엔지니어링 팀은 단순히 장애를 복구하는 것이 아니라, 더 신속하고 효율적인 문제 해결 문화를 구축할 수 있었습니다. 이제는 장애를 단순한 실패가 아니라, 시스템을 더욱 견고하게 만들 기회로 삼고 있습니다.
앞으로도 데이터&AI팀은 자동화, 모니터링, 그리고 AI의 힘을 적극 활용해 데이터 인프라를 지속적으로 발전시켜 나갈 것입니다. 반복되는 장애가 아닌, 더 나은 시스템을 위한 이정표를 만들어가기 위해서요.
그리고 Airflow 커뮤니티의 발전을 위해 좋은 자리를 마련해주신 Airflow Seoul Meetup 운영진 여러분께도 감사의 말씀 드립니다! 덕분에 다양한 인사이트를 공유하고, 실무 고민을 나누며 더욱 성장할 수 있는 뜻 깊은 시간이 되었습니다.
긴 글 읽어주셔서 감사합니다. 여러분의 Airflow와 데이터 파이프라인이 어제 보다 더 탄탄해지길 바랍니다. 🚀
Members
- Seokyun Ha, 하석윤 | Data Platform Team Leader
- Kyeonghoon Kim, 김경훈 | Data Engineer
- Imsong Jeon, 전임송 | Jr. Data Engineer