안녕하세요. 베이글코드 Data&AI 팀의 Data Engineer 김경훈입니다. 🙂
이번에 베이글코드에서 새로운 BI 툴로 Metabase를 도입했는데 그 과정에 대해서 소개해 드리려 합니다.
목차
1. 베이글코드의 Data Delivery
– Data Delivery 현황
– 추가적인 BI 툴 필요성 제기
2. Metabase 배포 과정
– EKS 환경 배포
– 초기설정
– 트러블 슈팅 과정
- 메모리 점유
- sync, scan 병목
- schema 하나당 데이터베이스 하나로 등록이 되는 문제
- driver 커스텀하기 (feat. clojure)
- 쿼리 timeout 문제
3. 마무리
베이글코드의 Data Delivery
Data Delivery 현황
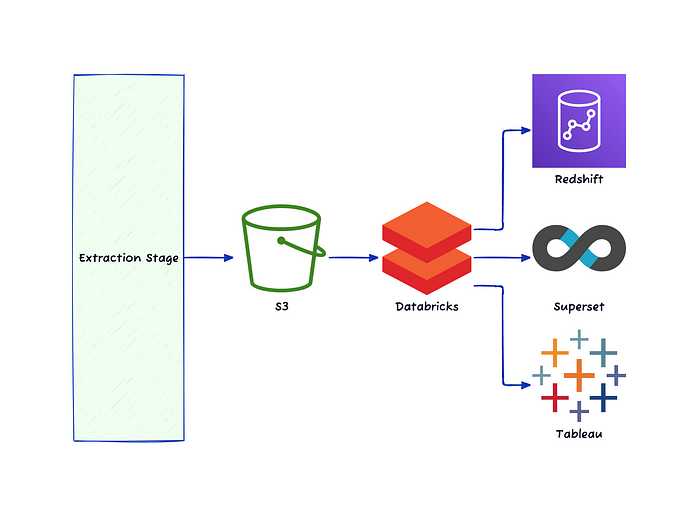
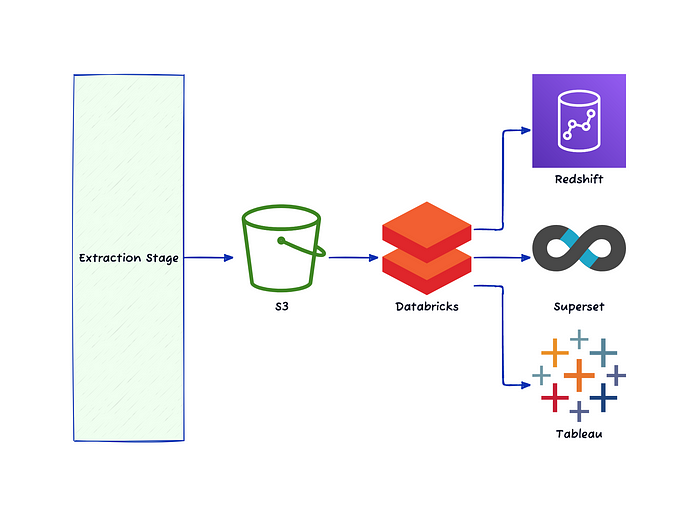
베이글코드에서는 데이터를 추출해서 S3에 저장 후 Databricks에서 가공해서 사용합니다. 기존에는 end-user에게 데이터를 제공하기 위한 툴로 Redshift, Tableau를 이용 중이었습니다.
그런데 테이블이 점점 늘어나면서 lock에 걸려서 write, read 시간이 오래 걸리고 비용 문제 등의 이유로 Databricks SQL warehouse를 통해 Superset으로 쿼리할 수 있도록 변경했고 Redshift와 Superset을 동시에 이용하는 과도기를 지나 Superset만을 이용하는 방식으로 변경했습니다.
Redshift를 제거하는 과정에 대해서 궁금하시다면 ‘Databricks SQL Serverless 도입기’를 참고해 주세요.
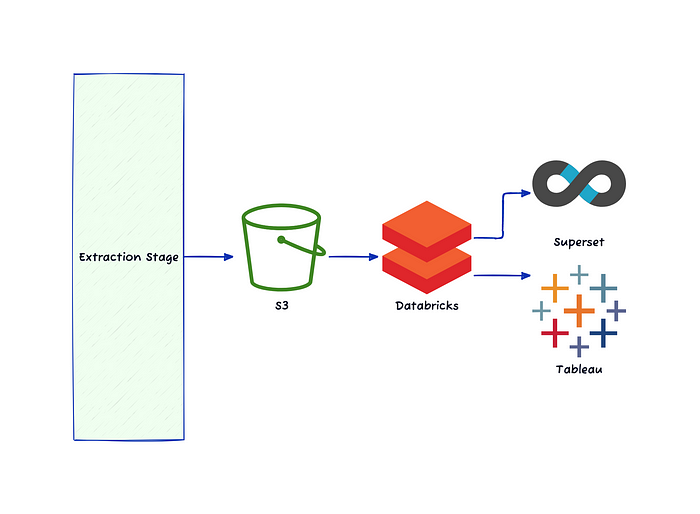
과도기를 지난 후 데이터를 사용하는 end-user가 사용할 수 있는 툴은 Superset과 Tableau 두 가지가 되었습니다.
직접 테이블에서 바로 쿼리를 해서 사용하고 싶을 때는 Superset으로, 시각화가 필요할 때는 Tableau를 이용하였습니다.
추가적인 BI 툴 필요성 제기
하지만 신작팀이 점점 늘어나면서 추가적인 BI 툴의 필요성을 느꼈습니다. 신작팀은 인원이 많지 않은 관계로 데이터를 직접적으로 다룰 수 있는 인원이 없는 경우가 많았습니다. 이 경우 데이터 팀에게 직접적으로 요청하는 방법이 존재하지만, 빠른 사이클이 필요한 신작팀에게는 일분일초가 소중합니다.
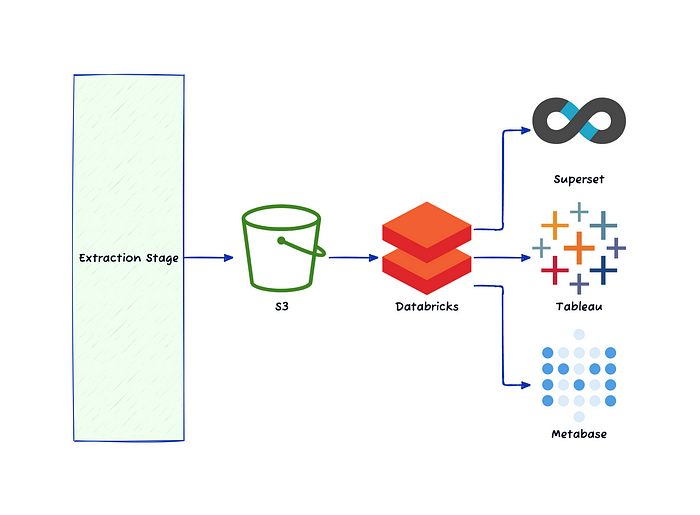
‘SQL 쿼리를 할 줄 모르는 사용자’도 ‘빠르게’ 데이터를 다룰 수 있는 BI 툴의 필요성을 느껴서 Metabase를 도입하게 되었습니다.
Metabase에서는 question이라는 기능을 통해 template화된 GUI 쿼리 툴이 존재하기 때문에 SQL을 모르는 사용자도 쉽게 쿼리를 할 수 있도록 해주고 자체 시각화 기능 및 alert 설정 등 다양한 기능이 있기 때문에 도입을 결정하게 되었습니다.
정리하자면 아래와 같습니다.
Superset: SQL 쿼리를 다룰 줄 아는 사용자가 데이터를 추출하기 위해 사용.
Tableau: SQL 쿼리를 다룰 줄 아는 사용자가 시각화를 위해 사용. 또는 SQL 쿼리를 모르는 사용자도 데이터 팀에 요청해 사용.
Metabase: SQL 쿼리를 다룰 줄 모르는 사용자가 빠르게 데이터를 다루거나 시각화할 때 사용.
Metabase 배포 과정
메타베이스를 도입 POC를 진행했던 1월에는 메타베이스 도입과 관련된 글이 많지 않아서 ‘Metabase의 공식 포스트’를 자세히 읽어보면서 진행했습니다.
메타베이스는 Manged Service와 Open Source 버전이 존재하는데 일단 Open Source 버전으로 작업을 진행하기로 했습니다.
이유는 크게 두 가지입니다.
- POC 단계이므로 비용을 지불할만한 가치가 있는지 아직 확신이 서지 않음.
- Managed Service에서는 Community Support Driver를 사용할 수 없음.
EKS 환경 배포
베이글코드 데이터 엔지니어팀은 쿠버네티스 환경으로 AWS의 EKS를 사용하고 있습니다. 대부분의 애플리케이션을 EKS 위에서 진행하고 있고 Helm Chart를 통해 배포하고 있습니다.
데이터 팀에서는 helm apply 하는 workflow를 템플릿화해서 사용하고 있기 때문에 helm chart를 통해 간단히 배포가 완료되었습니다.
혹시나 Metabase에 문제가 생길 경우를 대비해 Metabase의 데이터베이스를 디커플링했고 AWS RDS의 postgresql을 이용했습니다.
초기설정
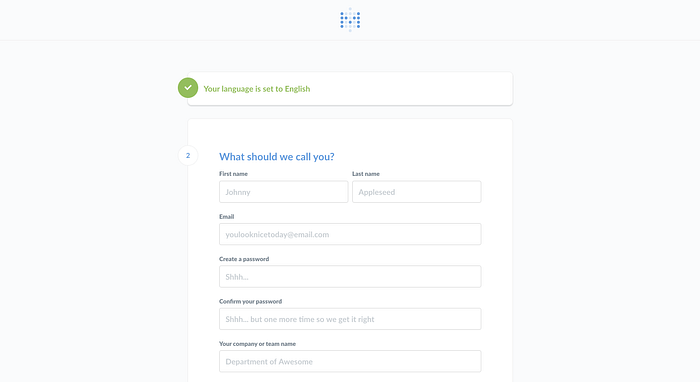
메타베이스를 deploy하고 처음 접속을 하게 되면 위와 같이 계정 설정 화면이 나오는데 이 계정이 첫 관리자 계정이 되니 관리 주체가 되는 개인 계정이나 팀 계정으로 아이디를 생성해 주시면 됩니다.
데이터 팀은 관리용으로 쓰는 계정이 따로 있기 때문에 해당 계정으로 아이디를 생성했습니다.
이후 관리자 계정으로 다양한 설정을 완료하시고 Database를 등록하시면 쿼리가 가능합니다.
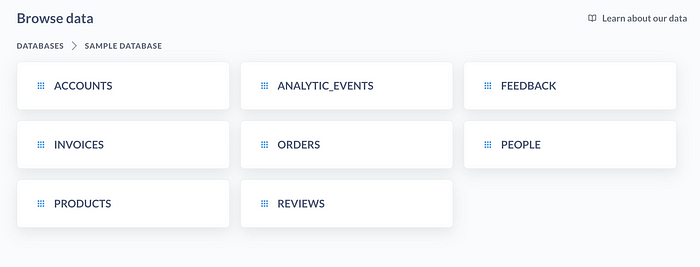
Sample Database. 등록된 데이터베이스의 테이블이 나온다.
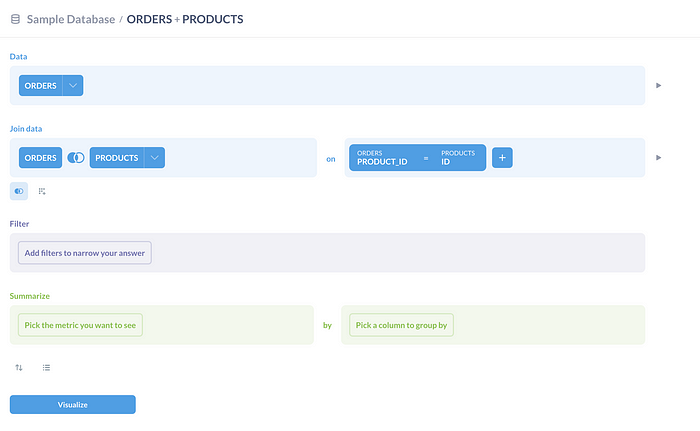
Metabase의 핵심 기능 중 하나인 Question 기능! 템플릿화된 GUI에서 클릭해서 쿼리가 가능하다.
Databricks community driver 등록
베이글코드에서는 데이터 레이크하우스로 databricks를 사용 중이기 때문에 databricks의 테이블을 등록하려 했습니다.
databricks가 spark 기반이므로 built-in spark driver로 당연히 될 줄 알았지만, 구조가 다른 것인지 spark driver로 등록을 할 수 없었습니다. 🫠
community support driver를 사용할 수밖에 없었고 마침 metabase 공식 사이트에 나와 있는 driver가 있기 때문에 해당 driver를 추가해서 사용했습니다.
해당 레포의 내용물을 복사하고 빌드해서 ECR에 업로드하는 ci를 추가적으로 만들고 다시 배포를 진행했습니다.
databricks driver를 이용하기 위해 Metabase용 sql warehouse를 생성해서 등록해 주었고 schema가 잘 보이고 sync도 문제없이 진행되는 줄 알았습니다만…
몇 가지 문제점이 발생했습니다.
트러블 슈팅 과정
1. 메모리 점유 현상
문제를 발견한 건 Metabase가 포함된 node가 재시작해서 다른 분들께서 제보를 주셔서 알게 되었습니다. 문제는 Metabase에 cpu, memory limit을 걸어두지 않아서 발생했습니다.

node 재시작 직전 지표를 보니 memory를 16.6GiB 사용 중이었고 그래프를 보니 거의 단조 증가함수처럼 증가하고 줄어들지는 않는 모습을 보였습니다. 🫢
아무리 데이터가 커도 아직 사용자가 없는데 꾸준히 16.6GiB를 사용하는 것은 이상한 모습이었기 때문에 문제를 알아보니 이미 비슷한 현상들이 여럿 제보되었습니다.
(글 작성 시점인 2024년 6월 28일 기준으로 아직 현재 진행형인듯 합니다. ☹️)
깃헙 이슈에서는 Metabase의 문제는 아니고 JVM의 문제다 라는 언급이 있긴 하나 일단 해결책이 중요했기에 해결책을 살펴보았습니다.
JAVA_TOOL_OPTIONS
에서 Xmx를 설정하면 최대 메모리가 설정되어 해당 메모리 이상 점유하지 않는다고 해서 해당 설정을 적용했고 추가로 다른 부분에 영향을 끼치지 않기 위해 dedicated node를 새로 만들어 Metabase만 사용할 수 있도록 했습니다.
하지만 일단 점유된 메모리가 내려가지 않는다는 점이 문제가 되었으므로 매일 오전 5시에 Metabase를 restart 하도록 하는 workflow도 설정해 두었습니다.
2.sync, scan의 병목현상
databricks classic sql warehouse를 이용했는데 왜인지는 모르겠지만
SELECT 1;
과 같은 단순한 쿼리도 여러 개가 수 많은 요청이 들어올 경우 병목 현상이 생깁니다.
일반적인 병목이라면 단순한
SELECT 1;
의 결과를 빠르게 처리하고 넘어가겠지만 시간이 오래 지나도 쿼리가 처리되지 않는 현상이 있었습니다.
사용했던 community driver가 쿼리를 실행하기 전 healthcheck용 핑으로
SELECT 1;
을 사용하고 있었기 때문에 많은 테이블을 sync 하기 전 핑을 보내고 해당 쿼리가 병목이 되었습니다.
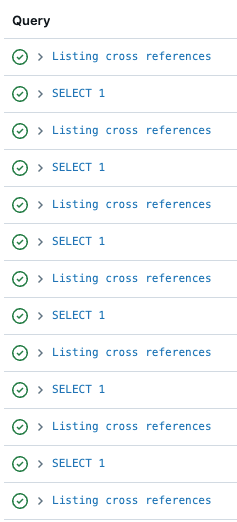
Classic SQL Warehouse의 경우는 비용 절감을 위해 특정 시간 동안 사용되지 않으면 꺼지도록 설정을 해두었는데 clsuter가 시작되는데 걸리는 시간 때문에 사용자 경험이 나빠지는 것은 물론 sync가 실패하는 경우도 존재해서 이를 Serverless SQL Warehouse로 변경해서 해결했습니다.
신기하게도 Serverless SQL Warehouse 사용 후
SELECT 1;
에 대한 병목현상도 같이 사라졌습니다.
또한 테이블의 양 자체도 문제가 되었습니다.
Metabase에서는 테이블을 등록할 때 sync, scan이 존재하는데 아래와 같은 쿼리를 이용합니다.
sync
SELECT
TRUE
FROM
"your_schema"."your_table_or_view"
WHERE
1 <> 1
LIMIT 0scan
SELECT
"your_table_or_view"."column" AS "column"
FROM
"your_schema"."your_table_or_view"
GROUP BY
"your_table_or_view"."column"
ORDER BY
"your_table_or_view"."column" ASC
LIMIT 1000문제가 되었던 부분은 scan입니다. 테이블의 크기가 크다 보니 GROUP BY 연산이 있기 때문에 특정 테이블들은 scan 시간이 수 시간이 걸리기도 했고 cluster를 계속 점유하고 있어 다른 테이블의 sync, scan이 안 이루어지는 경우가 발생했습니다.
이 부분은 sync는 daily로, scan은 manual trigger를 했을 때만 실행되도록 설정을 변경해서 해결했습니다.
sync와 scan에 관해 궁금하신 분은 해당 문서를 참조하시기 바랍니다.
3.schema 하나당 데이터베이스 하나로 등록이 되는 문제
이 문제는 Metabase의 문제라기 보다는 community driver 자체의 문제점이었습니다. 메타베이스에서 테이블을 보기 위해서는 database -> schema -> table 순으로 클릭해서 볼 수 있습니다.
그런데 community driver에서는 schema를 database처럼 취급해서 등록되었습니다. 모든 스키마를 등록하기 위해서 스키마를 하나하나 등록해 주어야 하였고, 가장 큰 문제는 다른 스키마끼리 join이 안된다는 점이었습니다.

Metabase는 데이터베이스 간의 join을 지원하지 않는데 드라이버 문제로 스키마끼리 다른 데이터베이스로 취급해서 join이 안되는 문제였습니다. 화면에서는 Card does not exist라고 뜹니다.
해당 문제 해결을 위해 다른 드라이버를 찾던 중에 Unity Catalog table을 등록할 수 있도록 한 드라이버를 찾았습니다.
다만, 드라이버가 Unity Catalog enable된 것을 타겟으로 했기 때문에 코드를 살펴보면 information schema table이 필요한 것을 알 수 있습니다.(Metabase와 driver 코드들은 모두 clojure로 구성되어 있습니다.)
;; workaround for SPARK-9686 Spark Thrift server doesn't return correct JDBC metadata
(defmethod driver/describe-database :sparksql-databricks-v2
[_ database]
{:tables
(with-open [conn (jdbc/get-connection (sql-jdbc.conn/db->pooled-connection-spec database))]
(set
(for [{:keys [database tablename tab_name table_name table_schema], table-namespace :namespace} (jdbc/query {:connection conn} ["select * from information_schema.tables"])]
{:name (or tablename tab_name table_name table_schema) ; column name differs depending on server (SparkSQL, hive, Impala)
:schema (or (not-empty database)
(not-empty table_schema)
(not-empty table-namespace))})))})데이터 팀에서는 Unity Catalog migration을 진행 중인 상황이라 Unity Catalog가 아닌 카탈로그에 대해서도 테이블을 등록할 필요가 있었고 고민을 하던 중 information_schema를 직접 만들면 되겠다는 생각이 들었습니다.
마침 기존에 다른 목적으로 모든 스키마와 테이블을 기록해 둔 테이블이 있었고 코드에서 information_schema.tables를 해당 테이블로 변경해 빌드해서 카탈로그 단위로 등록하는 것에 성공했습니다.
다만 또 다른 문제가 발생했는데, 커스텀 한 드라이버에서 몇몇 테이블에서 column을 읽어오지 못해 sync가 안되는 현상이 발생했고 아무리 다시 sync를 진행해도 해결되지 않았습니다.
특정 테이블은 읽는 것이 가능했기에 해당 테이블들의 차이점이 무엇인지를 찾다 보니 column중에 ‘dt’를 가진 테이블이 sync가 안 된다는 것을 발견했습니다.
직접 트러블 슈팅을 하기 위해 Admin settings — Troubleshooting — Logs를 살펴보았습니다.(k8s pod에서 보이는 log와 동일합니다.)
확인 결과 아래와 같은 로그를 얻었습니다.
… truncated
ERROR: duplicate key value violates unique constraint
"idx_uniq_field_table_id_parent_id_name_2col",
Detail: Key (table_id, name)=(42331, dt) already exists., … 552 more짐작하던 대로 ‘dt’ column에 문제가 있는 것이 맞았습니다. 로그를 살펴보면 table 42331에서 dt라는 key가 duplicate 됐다는 것을 알 수 있습니다.
하지만 databricks 상에서 describe table을 해보았을 때 dt column은 하나밖에 존재하지 않았고, 있더라도 databricks상에서 중복된 column 명을 허용할 리가 없다고 생각했습니다.
이상함을 느끼고 jdbc connection을 재현해 보기로 했습니다.
;; workaround for SPARK-9686 Spark Thrift server doesn't return correct JDBC metadata
(defmethod driver/describe-table :sparksql-databricks-v2
[driver database {table-name :name, schema :schema}]
{:name table-name
:schema schema
:fields
(with-open [conn (jdbc/get-connection (sql-jdbc.conn/db->pooled-connection-spec database))]
(let [results (jdbc/query {:connection conn} [(format
"describe %s"
(sql.u/quote-name driver :table
(dash-to-underscore schema)
(dash-to-underscore table-name)))])]드라이버의 코드를 살펴보면 처음 database를 등록할 때 describe를 실행하는 것을 알 수 있습니다.
드라이버에서 사용하는 똑같은 파라미터를 주입하고 커넥션을 만들기 위해 파이썬 코드를 구성했습니다.
import pyodbc
import os
os.environ['DYLD_LIBRARY_PATH'] = '/Library/simba/spark/lib'
# Define the connection parameters (adjust these with your actual credentials and paths)
host = "[[HOST NAME]]"
port = 443 # Default HTTPS port
http_path = "/sql/1.0/warehouses/[[REDACTED]]"
app_id = "[[REDACTED]"
app_secret = "[[REDACTED]]"
catalog = "[[CATLAOG NAME]]" # Typically default if not specified
# Construct the connection string
connection_string = f"""
DRIVER=/Library/simba/spark/lib/libsparkodbc_sb64-universal.dylib;
HOST={host};
PORT={port};
HTTPPath={http_path};
SSL=1;
ConnCatalog={catalog};
AuthMech=11;
Auth_Flow=1;
Auth_Client_ID={app_id};
Auth_Client_Secret={app_secret};
"""
# Connect to Databricks using the connection string
conn = pyodbc.connect(connection_string, autocommit=True)
# Create a cursor object and execute SQL
cursor = conn.cursor()
cursor.execute("DESCRIBE {table name};")
# Fetch and display the results
rows = cursor.fetchall()
for row in rows:
print(row)
# Close the cursor and connection
cursor.close()
conn.close()위 코드를 실행하기 위해서는 databricks odbc driver를 다운받으시고 가이드를 따라해주셔야 합니다.
Column Names: ['col_name', 'data_type', 'comment']
('id', 'string', 'ID')
('ts', 'bigint', 'unix timestamp (in milliseconds)')
...truncated for security
('dt', 'date', '')
('# Partition Information', '', '')
('# col_name', 'data_type', 'comment')
('dt', 'date', '')실행하면 위와 같이 col_name, data_type, comment로 각각의 column 내용이 나옵니다.
여기서 보면 dt가 두 번 존재하는 것을 알 수 있는데 databricks에서는 # Partition Information이라는 칼럼이 존재합니다. 이것의 뒤에 존재하는 것들은 파티션 정보를 표시하기 위한 정보들이기 때문에 실제로 쿼리를 실행 할 때는 해당 column을 무시한 채 실행합니다.
다만 코드상으로 describe를 했을 때 해당 column도 같이 드러나는 것을 확인했고 해당 부분이 문제라고 판단해서 직접 driver를 커스텀하기로 했습니다.
4.driver 커스텀하기 (feat. clojure)
Metabase와 driver는 clojure로 구성이 되어있습니다.
비슷한 형식의 언어를 사용해 본 적이 없었기 때문에 완전히 새로 공부해야 했습니다. 이틀 정도 기본 문법을 공부했고 다행히도 GPT의 도움을 받을 수 있었기 때문에 훨씬 수월하게 작업할 수 있었습니다.
목표로 하는 코드 수정 부분이 명확했기 때문에 GPT에게 해당 부분의 중복을 제거하는 코드를 짜도록 도움을 부탁했습니다.
GPT가 짠 코드가 바로 원하는 대로 동작하지는 않았기에 살짝 수정을 거쳐 나온 코드가 아래 코드입니다.
;; workaround for SPARK-9686 Spark Thrift server doesn't return correct JDBC metadata
(defmethod driver/describe-table :sparksql-databricks-v2
[driver database {table-name :name, schema :schema}]
{:name table-name
:schema schema
:fields
(with-open [conn (jdbc/get-connection (sql-jdbc.conn/db->pooled-connection-spec database))] ; Open with-open
(let [results (jdbc/query {:connection conn} [(format
"describe %s"
(sql.u/quote-name driver :table
(dash-to-underscore schema)
(dash-to-underscore table-name)))]) ; Close jdbc/query vector and let vector
seen (atom #{})] ; Close let vector for results and seen
(->> results
(map-indexed (fn [idx result]
(assoc result :database-position idx))) ; Close map-indexed function
(filter (fn [{:keys [col_name data_type]}]
(valid-describe-table-row? {:col_name col_name, :data_type data_type}))) ; Close filter function
(remove (fn [{:keys [col_name]}]
(let [already-seen (contains? @seen col_name)] ; Open let in remove
(swap! seen conj col_name) ; Action in let
already-seen))) ; Close let in remove, close remove function
(map (fn [{col_name :col_name, data_type :data_type, database-position :database-position}]
{:name col_name
:database-type data_type
:base-type (sql-jdbc.sync/database-type->base-type :hive-like (keyword data_type))
:database-position database-position})) ; Close map function
set)))}) ; Close ->>, close with-open, close method map, close defmethoddescribe 후 ‘already-seen’에 들어 있는지 확인하고 있다면 제거하도록 했습니다.
해당 코드로 driver를 커스텀하고 다시 build를 했고 다행히도 생각했던 원인이 맞아서 문제가 해결됐습니다.
5.쿼리 timeout 문제
테이블들을 하나씩 보면서 테스트하던 도중 테이블 사이즈가 큰 테이블에서 쿼리 timeout으로 실패하는 경우가 있었습니다.
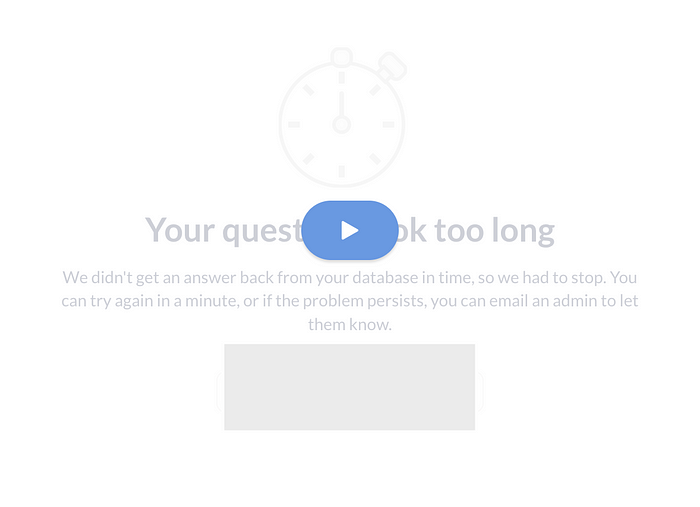
시간이 오래 걸리는 것에 대해서 위와 같이 Your question took too long이라는 문구와 함께 실행이 취소되었습니다.
해당 이슈를 검색해 본 결과 비슷한 이슈를 지닌 사람들이 있었고 nginx를 사용 중이던 사람들에게 공통적으로 발생하는 현상인 것을 알 수 있었습니다.
nginx는 proxy-read-timeout이 기본 값이 60초였고 대략 Your question took too long이라는 문구가 뜨는 시간이 비슷했기에 해당 문제라고 생각을 하고 설정을 변경했습니다.
nginx의 proxy-read-timeout을 3600으로 늘렸고 변경 후 10분까지는 위 화면이 뜨지 않는 것으로 보아 nginx 쪽의 문제는 해결된 것으로 생각했습니다. 다만 3600으로 설정했는데도 10분까지 밖에 되지 않았던 것은 Metabase 자체의 설정 때문이었습니다.
마무리
길고 길었던 배포 과정 후에 서비스를 홍보하기 위해 베이글코드 내부에서 진행하는 TechTalk에 참여하기도 하고 Hands-on 세션을 만들어서 진행했습니다.
Databricks와 Metabase를 연결하실 분들은 현재 Metabase 로드맵을databricks official driver가 paid feature로 예정되어 있으니 참고하시면 좋을 것 같습니다.
Metabase를 배포하면서 많은 트러블 슈팅 과정을 겪었는데 확실히 UI 상으로는 SQL에 익숙하지 않으신 분들도 사용하기 편해 보입니다.
이외에도 CSV를 export해서 테이블로 사용하거나 goal line 도달 시 slack, email로alert 등 다양한 편의성 기능이 있어 앞으로의 기능들도 기대가 됩니다.
워낙 다양한 기능이 있어 superset, tableau 등 다른 BI 툴과도 역할이 겹치는 부분이 많아 도입하실 때 어떤 목적을 가지고 사용하는 건지 명확히 하고 도입하면 좋을 것 같습니다.
긴 글 읽어주셔서 감사합니다. 😄
Ref
https://www.metabase.com/docs/latest/installation-and-operation/start
https://www.metabase.com/docs/latest/configuring-metabase/setting-up-metabase
https://www.metabase.com/data_sources/spark-databricks
https://github.com/metabase/metabase/blob/master/docs/databases/sync-scan.md?plain=1
https://github.com/metabase/metabase/issues/12060
https://github.com/Brigad/metabase-sparksql-databricks-driver
https://docs.databricks.com/en/integrations/odbc/index.html
https://github.com/metabase/metabase/issues/12423
https://www.metabase.com/docs/latest/configuring-metabase/environment-variables