
안녕하세요, 베이글코드 데이터 엔지니어 하석윤 입니다.
오늘은 베이글코드 데이터&AI팀의 메타스토어를 Hive Metastore에서 Unity Catalog로 전환한 여정을 소개드리고자 합니다.
왜 Unity Catalog를 도입하게 되었나요?
베이글코드의 DATA&AI 팀은 2018년부터 Databricks를 활용하여 데이터 웨어하우스의 기반을 구축하고, 사내의 데이터 기반 의사결정을 지원해 왔습니다. 현재 약 10,000여 개의 테이블을 ETL, 데이터 분석 및 활용에 사용하고 있습니다. 그동안 이 모든 테이블은 Databricks의 Hive Metastore에서 관리했습니다.
2021년, Databricks는 새로운 Metastore 솔루션인 Unity Catalog를 발표합니다. 하지만 데이터 엔지니어로서 실무에서 Unity Catalog의 임팩트를 체감하기까지는 여러 장애물이 있어 시간이 걸렸습니다. 그래도 DAIS(Databricks AI Summit) 컨퍼런스에 다녀온 팀원들이 테이블 계보(Table Lineage)나 Serverless Compute와 같은 기능들을 정리해 공유해 주셨고,
팀에서는 “이 기능을 언제쯤 써볼 수 있을까?”, “UC가 있다면 작업에 정말 도움이 될 것 같다”고 기대했습니다.
Databricks는 매력적인 신기능들을 지속적으로 출시했지만, Unity Catalog 환경에서만 지원 하는 경우가 종종 있었고, Hive Metastore를 사용하는 저희는 기능들을 도입하고 싶어도 도입하지 못하는 상황이었습니다. 제약 사항을 더 이상 방치할 수 없다고 생각하게 된 저희는 2024년 상반기 프로젝트로 ‘Unity Catalog 마이그레이션’을 계획고, 약 5개월간의 과정 끝에 데이터 팀의 Metastore를 Unity Catalog로 성공적으로 이전했습니다!
왜 Databricks는 Unity Catalog를 출시했는가?
Databricks의 테크 블로그에 기고된 “Understanding Unity Catalog”라는 아티클을 읽어보면, Unity Catalog를 개발하게 된 이유와 히스토리를 엿볼 수 있습니다. 아티클의 내용을 정리하면 아래와 같습니다.
- Databricks 사용자 중에 Multi-Workspace를 사용하는 경우가 종종 있었다고 합니다. 이 Workspace들은 하나의 데이터 소스에서 데이터를 읽고 사용했는데, 같은 Access Control을 Workspace 마다 반복 진행하는 게 번거로웠다고 합니다. 이것은 Hive Metastore가 Workspace 레벨로 존재하기 때문입니다.
- Hive Metastore의 경우, Schema 전체를 허용해 주거나 개별 Table을 일일이 허용해 주어야 했습니다. 이것은 새로운 테이블이 추가될 때마다 접근 정책을 변경해야 하는 번거로움이 있었습니다.
- S3와 같이 External Location에 접근하는 경우, 그 접근 권한이 Cluster의 Instance Profile로 관리됩니다. 이것은 유저가 해당 Cluster를 사용할 수 있다면 그 Cluster에 부여된 모든 권한을 인계받는 것을 말합니다. 이것은 세밀한 보안 컨트롤을 어렵게 만들었습니다.
- Hive Metastore는 이제 옛날 스타일의 메타 저장소입니다. Table Lineage, Access Pattern, Data Discovery 관련해 기능이 부족합니다.
위의 이유와 불편함 점들 때문에 Databricks는 Unity Catalog라는 “새로운 Data Governance 모델”을 개발하고 출시했습니다.
마이그레이션을 위한 사전 작업들
Hive Metastore에서 Unity Catalog로 전환하기 위해서 사전에 필요한 작업들이 꽤 있습니다.
UCX
Databricks에서는 Unity Catalog 마이그레이션을 돕기 위해 UCX라는 도구를 제공하고 있습니다. 마이그레이션 과정에서 UCX 도구를 검토고, UCX에서 제공하는 Migration Readiness를 보며 저희가 마이그레이션 과정에서 필요한 사항을 점검습니다.
UCX 도구를 실행하면, Workspace에 존재하는 모든 Databricks 객체의 정보를 수집합니다. Table 뿐만 아니라 Job, Compute, SQL Warehouses와 심지어 User Account에 대한 정보를 모두 수집한 후, 이를
ucx
데이터베이스 아래에 저장해둡니다. UCX에서는 이를 바탕으로 Unity Catalog와 호환성을 체크하는데요.
- DBR 13 이하 버전을 사용하는 Job Compute 목록
- Databricks Legacy Group의 목록
- Incompatible global init script
다양한 측면에서 Unity Catalog 마이그레이션이 가능한지를 검토하고, 이에 대한 보고서를 제공합니다. 제공된 보고서는 저희가 Unity Catalog를 사용하기 위해 준비해야 할 요소를 놓치지 않고 파악하는 데에 큰 도움이 되었습니다. 그리고 구체적인 Readiness 수치를 알려주기 때문에 초기에 마이그레이션 준비를 잘 하고 있는지 가늠하고 방향을 수립하는 데에 도움이 되었습니다.
마이그레이션을 위한 보고서를 제공하는 것뿐만 아니라 마이그레이션의 전체 과정을 UCX로 진행할 수도 있습니다! 저희는 파이프라인을 GitOps로 관리하는 부분이 있어서 스크립트를 적용하기는 어려웠고, Workspace-local Group을 Account Group으로 전환하는 과정에서만 UCX 마이그레이션 스크립트의 도움을 받았습니다.
Migrate to Shared Mode Cluster
Unity Catalog를 사용하기 위해서는 기존의 “No Isolation Share” 모드 클러스터를 “Shared” 모드 클러스터로 변경해 주어야 합니다. 이는 Databricks의 클러스터 레벨에서 이뤄지는 Access Control 정책과 관련 있습니다.
Databricks는 여러 유저가 하나의 Spark 클러스터를 공유하며 사용할 수 있는 모드를 지원합니다. 이 과정에서 각 유저가 사용하는 데이터에 대한 격리와 적절한 권한 관리가 필요합니다.
본래 No Isolation Share 모드는 “Standard 모드”라는 이름이었고, Databricks에 공용 클러스터를 운영하기 위해선 이를 사용했습니다. “Isolation”라는 표현은 유저 간의 자원 격리가 적절히 이뤄지는가에 대한 표현인데요. Databricks 보안팀은 Standard 모드(현재의 No Isolation Share 모드)에서 관리자 권한을 가진 유저의 자격 증명이 노출될 가능성이 있고, 이를 통한 권한 상승(Privilege Escalation)이 가능한 보안 취약점이 있음을 발견하고 조치습니다.
Databricks에서 이 취약점에 대해 분석한 내용을 “Admin Isolation on Shared Clusters” 아티클에서 제공하고 있습니다. 자세한 내용은 해당 아티클을 읽어보시면 도움이 될 것 같습니다.
Unity Catalog는 Data Governance를 위한 메타스토어 입니다. Databricks 측에서는 이런 보안 취약점을 대응하고, 보안을 확보하기 위해 Unity Catalog와 통합을 선택습니다. No Isolation Shared 모드는 클러스터에 접근할 수 있다면 그 클러스터에 부여된 Instance Profile의 모든 권한을 공유 받았습니다. 반면에 보안이 향상된 Unity Catalog의 메커니즘을 사용하면 데이터 접근이 유저에게 부여된 ACL을 기준으로 이뤄지게 됩니다.
저희 팀은 데이터 EDA와 클러스터 재사용을 위해 공용으로 사용하는 클러스터를 No Isolation Share 모드로 사용하고 있었습니다. Spark 클러스터에서 Unity Catalog 기능을 사용하기 위해서는 Databricks Runtime 11.3 LTS 이상 버전과 Shared Mode 클러스터를 사용해야만 했습니다. 그래서 마이그레이션 과정에서 팀에서 사용하는 모든 종류의 클러스터(All-purpose, Job Compute)의 DBR 버전을 일괄 15.4 LTS 버전으로 올려주었습니다. 결과적으로 마이그레이션 작업을 통해 클러스터 보안 관점에서도 취약 부분을 점검하고 개선 하는 데에 많은 도움이 되었습니다.
다만, 아쉬운 점도 아직 존재하는데요. Shared 모드에서는 Spark Context나 RDD API와 같은 Spark의 low-level resource에 접근할 수 없습니다. 게다가 Spark ML이나 GPU attachment도 불가능한 상황이라 이런 경우에는 Single User 모드의 클러스터 만들어 사용하고 있습니다.
Spark API Limitations on Unity Catalog Shared Mode Cluster

바로 위의 문단에서 언급했던 것처럼 Unity Catalog의 Shared Mode로 동작하는 클러스터는 아래와 같은 제약이 있습니다.
- RDD API are not supported
- SparkContext, SqlContext are not supported
- 그외 다수…
대부분의 Spark 코드가 Spark Session
spark
를 사용하고 있었으나, 몇몇 오래된 코드에서는
sc
(SparkContext)나
sc.parallel()
를 사용하는 경우가 있었습니다. 데이터&AI팀은 모든 ETL 코드를 GitOps로 관리하고 있어, 전수 조사 후 Spark Session을 사용하도록 코드를 변경하는 작업을 진행습니다.
Workspace-local Group -> Account Group

Databricks의 유저 집합인 Group도 기존에는 Workspace 레벨에서 관리하는 객체였는데, 이것이 Account 레벨에서 관리하는 객체로 변경해 주어야 했습니다.
Account Group으로 마이그레이션은 UCX라는 Databricks의 UC 마이그레이션 도구를 활용습니다. UCX에서 Workspace-local Group에 부여된 권한들을 수집해 테이블로 저장해두면, 그걸 UCX의 script를 통해 새로 생성한 Account Group에 반영하는 방식으로 진행했습니다.
Delta-lake Migration
Unity Catalog 마이그레이션을 진행하며 기존에 Hive Metastore에 등록한 테이블을 Delta-lake 테이블로 전환하는 과정도 함께 진행했습니다.
Hive Metastore 환경에서도 Delta-lake 테이블을 사용하고 있었으나, 일부 테이블에만 적용되어 있었고, 전반적인 테이블은 Parquet 포맷을 기반으로 하는 테이블이었습니다. 당시 상태 그대로 Unity Catalog 마이그레이션 하는 것도 가능합니다만, 데이터를 저장하는 방식이 Drop and Recreate 였기 때문에 Unity Catalog에서 지원하는 Table Lineage 기능이 지원되지 않았습니다.
그래서 Unity Catalog 마이그레이션을 진행하면서 Parquet 테이블을 Delta 테이블로 전환하고 업데이트 로직도 이에 맞게 변경했습니다.
테이블을 Parquet 형식으로 저장하고 관리할 때는, 테이블 Versioning을 지원하기 위해 S3에 각 Workflow 실행마다 다른 경로에 데이터가 저장되도록 구성했는데요. Delta-lake로 마이그레이션 한 후에는 단일 경로에 테이블을 저장하면서도 히스토리를 Delta Log로 저장하고 웹 콘솔에서 확인할 수 있게 되어 관리 방식이 간소화되었습니다.
그리고 마이그레이션 과정 중에는 Hive Metastore와 Unity Catalog 동시에 테이블을 유지해야 할 때도 있었는데요. 테이블을 Delta-lake 포맷으로 관리하고, Hive Metastore와 Unity Catalog에 존재하는 두 테이블이 같은 S3 Location을 바라보도록 만들면, S3의 데이터에 변경이 발생하여도 양쪽에서 변경 사항을 모두 볼 수 있습니다. 저희는 이 방식으로 마이그레이션으로 인해 발생하는 다운 타임을 컨트롤고, 사용자분들이 three-level namespace에 적응하실 수 있도록 버퍼 기간을 둘 수 있었습니다.
Start Migration!
마이그레이션을 위해 사전 준비 할게 좀 많았네요;; 이런저런 준비 작업을 하다 보니 어느새 마이그레이션을 결심한 시점으로부터 두 달 정도 지나 있었습니다! (이럴 수가…)
Catalog 구조 설계
본격적인 마이그레이션을 진행하기에 앞서 UC에 새로 도입되는 Catalog를 고려해 현재 데이터베이스 구조를 다시 설계하자는 의견이 있었고, 이를 위해 저희는 UC 환경에 맞는, three-level namespace에 맞는 Catalog 구조를 먼저 잡기로 습니다.
베이글코드는 Club Vegas 게임을 관리하는 “CVS”팀과 신작 게임을 개발하고 런칭하는 “EXP”팀, “PKC”팀 등이 존재합니다. 어떤 테이블은 게임 스튜디오의 데이터만 존재하는 경우도 있었구요. 어떤 테이블은 앱들의 KPI를 모아서 하나의 테이블에 모아두는 경우도 있었습니다.
Catalog 구조를 설계할 때, 의견이 두 갈래로 나뉘었는데요. Catalog 이름을 Bronze, Silver, Gold 레이어에 대응되도록 설정해 메달리온(Medallion) 아키텍처를 그대로 반영하자는 의견, 그리고 스튜디오 별로 Catalog를 부여하여 그들의 데이터를 한 곳에 분류하자는 의견이 있었습니다.
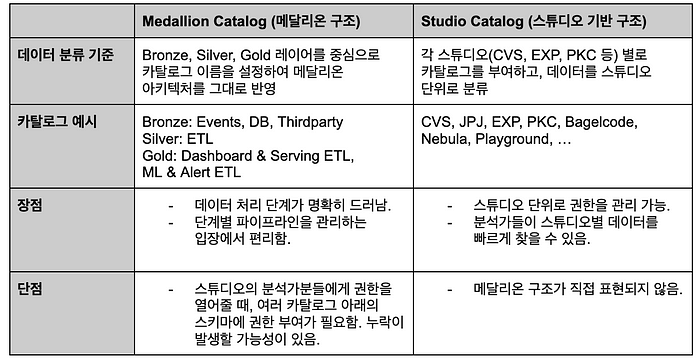
저희는 스튜디오 기반 카탈로그 구조를 채택했습니다! 사내 Access Control 정책을 고려했을 때, 데이터 분석가분들이 스튜디오 별로 접근 권한을 요청하시는 경우가 많았고, cross-studio로 데이터를 쿼리 하는 경우가 빈번하지 않다는 점이 근거가 되었습니다.
마이그레이션이 완료된 지금 돌아보면, 스튜디오 기반 구조가 Databricks 유저들에게 설득력 있었던 것 같습니다. Two-level namespace에서 three-level namespace로 쿼리를 변경하는 과정에서 조금의 번거로움이 있었지만, 오히려 자신이 원하는 스튜디오의 테이블과 데이터만 빠르게 찾아볼 수 있게 되었습니다. 그리고 메달리온 구조에 대한 부분은 Unity Catalog에서 제공하는 Schema Tagging을 활용하면 충분히 달성 가능한 요소 였습니다.
Migration one-by-one
저희는 원활한 마이그레이션을 위해 downstream이 없는 Leaf 테이블부터 마이그레이션을 진행습니다. 다행히 Unity Catalog를 활성화해도 Hive Metastore의 테이블에 여전히 접근하는 것이 가능했고, 골드 레이어인 Dashboard와 Data Serving을 위한 테이블을 먼저 Unity Catalog로 마이그레이션 했고, 그 후 실버 레이어의 ETL 테이블, 그리고 마지막으로 Events와 운영 DB의 테이블을 Unity Catalog로 마이그레이션 습니다.
데이터&AI팀은 모든 ETL 코드를 GitOps로 관리하고 있어서 마이그레이션을 하려면 Git으로 관리하는 ETL 코드 변경을 함께 진행해야 했습니다. ETL 코드에서 기존에
<SCHEMA_NAME>.<TABLE_NAME>
처럼 two-level로 접근하는 부분을 모두 앞에 catalog를 붙여
<CATALOG_NAME>.<SCHEMA_NAME>.<TABLE_NAME>
의 three-level로 변경해 주어야 했습니다. ETL 코드만 해도 1000개 정도 되었고, 각 코드마다 사용하는 SQL 코드나 Spark 코드가 달랐기 때문에 아무리 검수와 리뷰를 꼼꼼히 진행해도 PR 머지 후에 파이프라인에 장애가 발생하고 hotfix 하는 일도 종종 있었습니다. 그래도 3명의 작업자가 함께 변경사항을 리뷰하고, 또 장애에 대응 했기에 마이그레이션 작업이 잘 마무리 될 수 있었습니다.
scala/python UDF -> SparkSQL Functions
베이글코드의 ETL 파이프라인에서 Timezone 변환이나 Enum Type 핸들링 등을 위해 Spark UDF를 python 또는 scala로 정의하고 `spark.udf.register`로 등록해 사용하고 있었습니다. 그러나, UDF로 데이터를 가공하는 많은 쿼리가 Unity Catalog의 Shared Mode 클러스터에서 제대로 동작하지 않는 문제가 있었습니다.
당시 저희는 마이그레이션을 위해 Databricks Runtime을
13.3 LTS
또는
14.3 LTS
로 올렸는데요. Shared Cluster에서 UDF를 등록한 후 간헐적으로 에러가 발생했습니다.
이 문제를 해결하기 위해 여러 부분에서 고민했는데요. 저희가 해결한 방법은 python이나 scala로 Spark UDF를 정의하는 게 아니라, Spark SQL UDF를 정의하는 것입니다!
기존 UDF들의 코드와 패턴 Timezone 변환과 같은 단순한 작업은 Spark UDF가 아니라 Spark SQL의 함수를 조합해서 충분히 같은 결과를 얻을 수 있을 것이라고 예상했고,
spark.udf.register
로 등록해 쓰던 UDF 구문을 모두 아래와 같이 Spark SQL 구문으로 대체할 수 있다는 것도 발견습니다.
Spark SQL로 UDF를 정의하니 Unity Catalog에서도 Spark 작업들이 문제없이 실행 되었습니다!! 왜 SQL UDF로 전환하고서야 문제가 해결되었을까 그 원인을 찾아보았는데요. Python UDF와 Scala UDF가 Spark의 Catalyst Optimizer에게 black box와 같은 요소였습니다. Catalyst는 UDF의 내부 동작을 해석할 수 없기 때문에 쿼리가 제대로 최적화되지 않거나 Serialize 되지 않았습니다. Spark SQL UDF에 대해 더 살펴보고 싶으시다면, Databricks의 “Introducing SQL User-Defined Functions” 문서를 읽어보시길 추천 드립니다.
최종적으로는 Default Catalog인
main
카탈로그의
default
스키마 아래에 모든 Spark SQL UDF 함수를 등록하여 사용하고 있습니다! 기존에
spark.udf.register()
로 UDF를 매번 등록하는 번거로움도 없어졌고, Spark Performance 측면에서도 Optimizer가 변환 작업을 투명하게 파악할 수 있어 처리 시간이 전반적으로 개선되는 이득도 얻을 수 있었습니다!
Handle Hive-style Partitioned Tables
Unity Catalog 마이그레이션 과정에서 거의 모든 ETL 파이프라인이 일제히 터지는 큰 위기가 한번 있었는데요. Hive Metastore에서 Partitioned 테이블을 Unity Catalog로 마이그레이션 할 때였습니다. 저희는 events 테이블을 일별로 파티션 하여 저장하는데요. DDL 구문을 살펴보면 아래와 같습니다.
Hive Metastore에서는 Partitioned 테이블을 등록하면, 이를
MSCK REPAIR TABLE
명령어를 실행해 파티션 경로를 스캔하고, Hive Metastore에 저장합니다. 그런데, Unity Catalog에서는 다르게 동작했었는데요. 클라우드 스토리지의 객체 저장소를 기반으로 동작하기 때문에, 파티션을 쿼리 시점에 감지하고 이를 바탕으로 쿼리 과정에서 파티션 프루닝을 지원합니다.
문제는 Unity Catalog에서 Partitioned 테이블에 조회 쿼리를 할 때마다 파티션 경로를 listing 하는 것에 있었습니다. Hive Metastore의 동작과 다르게 쿼리에 파티션 조회라는 단계가 추가되면서 하위 파이프라인의 조회 성능에 문제가 발생고, 아주 많은 파이프라인이 Timeout으로 실패와 재시작을 겪었습니다.
다행히도 Databricks에서 파티션 조회에 대한 새로운 해결책을 개발했습니다! “Partition Metadata Logging”이라는 기능인데, Hive Metastore에서 파티션 정보를 저장해뒀던 것처럼 Unity Catalog에서도 등록된 테이블의 파티션 정보를 별도의 저장소에 저장하는 기능입니다.
이를 사용하기 위해서는 DBR 13.3 LTS 보다 높은 버전을 사용하고, 아래의 spark config를 클러스터에 설정해야 합니다.
spark.databricks.nonDelta.partitionLog.enabled true
그리고 기존에 생성했던 Partitioned 테이블에 대해 “MSCK REPAIR TABLE”를 사용해 파티션 경로 정보를 수집해 저장하도록 합니다. 이 기능이 파티션 정보를 어떤 방식으로 저장하는지는 Unity Catalog의 Storage Root에서 살펴보면 됩니다.
Unity Catalog에 테이블을 등록하면 고유한 “Table Id”가 생성되는데요. Storage Root 버킷에서 Partitioned 테이블에 부여된 Table Id에 대응되는 Partition Log 경로를 보면 Delta-lake의
_delta_log/
폴더처럼 로그가 기록된 모습을 확인할 수 있습니다. 파일 중 하나를 열어보면 아래와 같은 형식을 가지고 있습니다. Delta-lake의 Data Skipping 방식을 Partitioned 테이블에 대해서도 동일하게 구현한 기능이 아닐까 추측하고 있습니다.
_delta_logs와 비슷한 포맷을 가집니다
Unity Catalog로 마이그레이션한 모든 Partitioned 테이블에 Partition Metadata Logging 기능을 적용한 후, 조회 쿼리의 성능이 다시 향상되었고, 파이프라인의 Timeout 문제도 함께 해결되었습니다. 다만, 전체 클러스터에
spark.databricks.nonDelta.partitionLog.enabled
옵션을 반드시 적용해야 했습니다. 이미 Delta-lake 마이그레이션을 함께 진행하고 있었고, 근본적인 해결을 하려면 모든 Hive-style Partitioned 테이블을 Delta-lake 포맷의 Partitioned 테이블로 전환하는 과정이 필요 했습니다.

저희는 마이그레이션이 완료된 이후, 모든 Partitioned 테이블을 Delta-lake Partitioned 테이블로 전환습니다! 그리고 그 과정에서 Auto Loader를 적용할 수 있다면 함께 적용습니다.
그 결과, Partitioned 테이블이 있던 S3 버킷에 들어오는
GetObject
와
ListObjects
요청이 아주 크게 줄었습니다!! Partitioned Metadata 기능을 켰을 때는 기존 대비 34%로 감소고, Delta-lake와 Auto Loader까지 적용했을 때는 한 번 더 줄어서 기존 대비 10%까지 요청 횟수를 줄일 수 있었습니다.
After the Migration
External Data Tools Integrations
마이그레이션 이후엔 Databricks에서 데이터를 쿼리 하는 각종 서빙 서비스들을 이에 맞게 변경해 줘야 했습니다.
Tableau
- Unity Catalog를 지원하는 Tableau Desktop과 Simba ODBC Driver를 사용해야 합니다.
- 저희는 Tableau Desktop은 2021.4보다 높은 버전을 사용하고 있었지만, Simba ODBC Driver를 낮을 걸 사용하고 있었어서, 최신 버전을 사용하도록 팀에 전파하고 도움을 드렸습니다.
- 자세한 내용은 Databricks의 “Connect Tableau and Databricks” 문서를 참고하시길 바랍니다.
Superset
- 사내 데이터 분석가분들의 쿼리 플랫폼인 Superset도 마이그레이션 이후 작업이 필요했습니다.
- three-level namespace 방식을 지원하기 위해 버전을 v3.1 버전에서 v4.1 버전으로 업그레이드를 진행했고, Database Connection도 JDBC-SqlAlchemy 방식에서 Databricks의 databricks-python-connector를 사용하도록 변경습니다.
Datahub
- 사내 Data Discovery 도구인 Datahub도 변경이 필요했습니다.
- 기존에 Hive 플랫폼에서 ingestion 하던 방식에서 Unity Catalog에서 데이터를 ingestion 하도록 recipe을 수정하여 대응습니다.
널리널리 사용해보세요!
Unity Catalog로 전환하면서 기존 Databricks 사용자분들께 Unity Catalog가 무엇인지, 어떤 변화가 있는지, 그리고 새롭게 활용할 수 있는 기능들에 대해 안내 드릴 필요가 있었습니다. 이를 위해, Unity Catalog의 장점을 적극적으로 알리고 사용자들이 새 환경에 빠르게 적응할 수 있도록 다양한 노력을 기울였습니다.

전환 과정에서는 마이그레이션 중 실수나 버그로 인해 파이프라인 실패가 발생하면서 여러 사용자들에게 알림 폭탄이 전달된 경우도 있었습니다. 저희 마이그레이션 팀은 전환 과정에서 혼란을 최소화하고자 중요 작업마다 진행 상황을 슬랙을 통해 실시간으로 공유드렸습니다. 또한, 사내 세션을 통해 Unity Catalog의 개념과 전후 변화를 상세히 설명드리며 허들을 낮추데 노력습니다.
다행히도 마이그레이션이 완료된 지금은 사내 모든 사용자들이 Unity Catalog 환경에 완전히 적응습니다! 이전의 Hive Metastore보다 더 풍부한 메타데이터를 Unity Catalog 환경에서 누리고 활용하고 있습니다.
What we can do after?
마이그레이션 이후, 이제는 Databricks의 각종 신기능들을 마음껏 사용해보고 있습니다 ㅎㅎ
먼저 Databricks의 Genie Room을 적극적으로 사용하고 있는데요. Genie Room에 Unity Catalog의 테이블을 등록하여 데이터를 자연어로 쿼리하고 응답받고 있습니다. 이를 활용하여 사내 GPT 기반 슬랙봇인 “DAVIS”에서 Genie Room을 쿼리 백엔드로 활용하고 있습니다.
이를 통해 기존에는 Data Analyst 분들께 데이터와 시각화를 요청하고 결과물을 받는데, 최소 1시간에서 이틀 이상 걸렸다면, Genie Room 기반 슬랙봇은 1~3분 이내로 결과물을 받아올 수 있어, 사내의 빠른 비즈니스 결정을 지원할 수 있게 되었습니다!
Genie Room 기반 슬랙봇은 관련해서 저희에 맞게 튜닝하고 개선한 부분이 많아서 추후 별도 포스트에서 다뤄보도록 하겠습니다.
Unity Catalog에서 제공하는 Lineage 기능도 데이터&AI팀의 생산성을 높여주고 있습니다! Databricks Job에서 접근하는 Upstream 테이블과 Downstream 테이블을 추적할 수 있게 되었으며, 서로 의존관계에 있는 테이블을 Databricks 웹 콘솔에서 손쉽게 확인할 수 있게 되었습니다! 🙌
Spark Engine에서 이 기능을 어떻게 구현는지 궁금하여 이리저리 좀 찾아보았는데요. DAIS 2022 컨퍼런스의 “Discover Data Lakehouse With End-to-End Lineage” 영상에서 접근 방법을 살짝 볼 수 있었습니다.
Databricks의 Lineage는 Spark Dataframe의 Query Plan에서 Logical Plan을 파싱 하는 방식으로 Lineage를 구성하고 있었습니다. Logical Plan을 살펴보면,
Project
에 테이블 이름이 three-level namespace 형식으로 담깁니다. 이들을 파싱 하면, 테이블이 어떤 테이블을 조합하여 만들어지는 그 정보를 수집할 수 있습니다. Column-level Lineage의 경우는 조금 더 어려운 작업인데요. 트리 형태인 Logical Plan에서 마지막 요소의 Attribute 요소가 어떤 과정으로 만들어지는지를 역추적하여, 컬럼 별 upstream 컬럼을 찾는다고 합니다.
테이블 Lineage도 중요하지만, Databricks는 테이블이 아닌 Notebook, Job, Dashboard와 같은 요소들에 대한 Lineage도 고려습니다. 어떤 Notebook에서 Spark Query가 실행된다면, 그 Spark Query의 upstream 요소를 모두 수집하고, 이를 각 요소들의 의존성 그래프에 추가해준다고 합니다.
아쉽게도 이 기능은 현재 Unity Catalog OSS 버전에서는 구현되어 있지 않고, Databricks에서만 사용할 수 있습니다. [Github Issue] 그래서 OSS 버전을 고려하신다면 이 점을 염두해두셔야 할 것 같습니다.
마지막으로 Unity Catalog로 전환하면서 Databricks의 각종 System Table을 통해 저희의 Databricks Activity를 트래킹 하기 쉬워졌습니다. Billing 테이블을 통해 비용 대시보드를 만들어, Databricks 사용량을 손쉽게 모니터링하고 Alert을 구축할 수 있었습니다. 또, Databricks 환경에 대한 메타 정보를 자유롭게 쿼리 하면서 팀의 Visibility를 향상시킬 수 있었습니다.
Retrospective
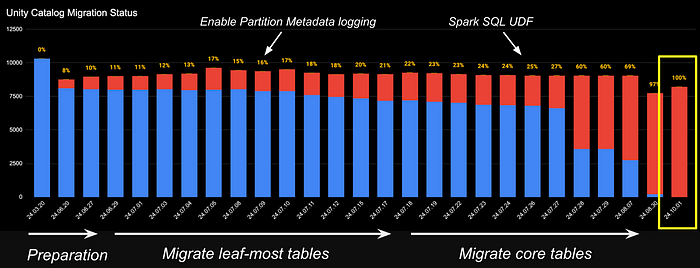
마이그레이션을 계획하고 마무리하는데, 꼬박 5개월의 시간이 걸렸습니다. 마무리하고 돌아보니 Github에서 150여 개의 PR을 만들었고, Jira 티켓도 120여 개를 만들어 진행하며 작업을 진행했습니다.
마이그레이션 과정에서 반복적인 작업도 많았고, 예상치 못한 문제로 인해 데이터 파이프라인에 장애가 발생하거나 여러 방면에서 많은 분들께 불편을 드리기도 했습니다. 하지만 이 과정을 통해 데이터&AI팀이 Databricks의 기능을 100%, 아니 그 이상으로 도약하는 중요한 발판을 마련했다는 것을 뿌듯하게 생각합니다. 팀 역량 측면에서도 마이그레이션 과정은 매우 값진 경험이었습니다. 수많은 Spark Error 상황을 마주하고, 전체 ETL 코드를 세세히 살펴보는 과정을 통해 Spark의 구조를 깊이 이해하고 Spark Application 개발과 디버깅 역량을 크게 향상시킬 수 있었습니다.
또, 8년간 쌓여 있던 데이터 웨어하우스의 구조와 보안 사항을 하나씩 점검하면서, 그동안 방치되거나 관리되지 않았던 테이블을 정리하고, ETL 코드의 형식에 대한 가이드라인도 작성하며 데이터&AI팀 내부의 ’찌꺼기(?)’를 많이 정리할 수 있었던 것도 큰 성과라고 느낍니다.
새로운 파이프라인 구조를 설계하거나, 혁신적인 데이터 애플리케이션을 만드는 과정도 멋지고 신나는 일이지만, 기존의 것을 돌아보고 새로운 표준을 도입하기 위해 분투하는 과정 역시 못지않게 중요하다고 생각합니다. 그래서 마이그레이션하는 과정에서 겪었던 ‘맨땅에 헤딩’한 경험과 순간들이 힘들었지만, 스스로 성장하고 역량을 기르는데 많은 도움이 되었습니다.
마지막으로, 마이그레이션 과정에서 밤낮없이 함께 고생해주신 Data Engineer 팀의 이정훈님, 정현진님께 진심으로 감사드립니다. 마이그레이션 과정에서 있었던 여러 어려움을 함께 고민하고 해결하는데 Databricks SA 분들도 많은 도움을 주셨습니다! 마지막으로 항상 응원과 격려를 보내주신 데이터&AI팀 팀원분들께도 깊은 감사를 전합니다!
Members
- Seokyun Ha, 하석윤 | Data Platform Team Leader
- Junhoon Lee, 이정훈 | Data Engineer
- Hyunjin Jung, 정현진 | Data Engineer Manager